Teil 1: Dem Algorithmus auf der Spur
In unserem letzten Blog haben wir Ihnen die Entstehungsgeschichte der kameraüberwachten Kekse erzählt. Zudem sind wir auf die Unterschiede von Machine Vision mit und ohne Deep Learning eingegangen. Die in der Geschichte angepriesene überlegene Software, welche auf Deep Learning basiert, haben wir jedoch nicht im Detail angeschaut. Gerne holen wir dies in einem ausgedehnten zweiteiligen Blog nach. Teil 1 befasst sich mit der Software- und Algorithmus-Architektur, Teil 2 geht der Frage nach der technischen Umsetzung nach.
Deep Learning
Obwohl in aller Munde, können sich die Wenigsten vorstellen, was genau hinter dem Buzzword Deep Learning steckt. In unserem Blog-Beitrag über die Unterschiede zwischen ‘klassischer’ und Deep Learning basierter Bildverarbeitung https://blog.it-logix.ch/machine-vision-mit-und-ohne-deep-learning/ bezeichnen wir die Essenz des Deep Learning Ansatzes als ‘trainierte’ Regeln. Genauer genommen besteht Deep Learning aus einer Klasse von speziellen Optimierungsalgorithmen, um Neuronale Netzwerke zu trainieren.


Links: Einfaches Neuronales Netzwerk mit mehreren Schichten. Rechts: Darstellung eines Convolutional Neural Networks (Faltendes Neuronales Netzwerk) zur Bildverarbeitung.
Neuronale Netzwerke
Den Grundbaustein für das Deep Learning legen die neuronalen Netzwerke. Sie sind inspiriert von Zellen und deren Verbindungen untereinander in einem Hirn. Ein Netzwerk besteht aus mehreren Ebenen, welche miteinander verbunden sind. Die Verbindungen entsprechen dabei den Synapsen einer Zelle, die Zellen wiederum den Aktivierungsfunktionen des Neuronalen Netzwerkes. Die Aktivierungsfunktionen entscheiden, basierend auf den Werten der eingehenden Verbindungen, ob am Ausgang der Zelle eine 1 oder eine 0 weitergeleitet wird. Der Wert am Ausgang wird wiederum über Gewichtungen weitergeleitet zur nächsten Aktivierungsfunktion. Das erlernen genau dieser Gewichtung entspricht dem ‚trainieren‘ der Regeln.
Auf dem Bild sehen wir eine einfache Form eines Neuronalen Netzwerkes. Das dargestellte Netzwerk hat eine sehr geringe Tiefe. Als tief werden Netzwerke mit mindestens einer Mittelschicht an Neuronen (Zellen) zwischen der Eingangs- und Ausgangsschicht bezeichnet. Zeitgemässe Netzwerke haben zum Teil hunderte von Schichten. Das dargestellte Netzwerk hat eine Eingangsschicht mit 6 Neuronen, und eine Ausgangsschicht mit einem Neuron. Dazwischen sind zwei Mittelschichten (oder auch versteckte Schichten). Ein solches Netzwerk wird als Multilayer Perceptron bezeichnet.
Es könnte zum Beispiel genutzt werden, um Vorhersagen über die Qualität eines Kekses zu treffen, bevor dieser überhaupt entsteht. So könnten Eingabeparameter etwa den Feuchtigkeitsgehalt des Teiges, die Temperatur des Ofens, die Backzeit und weitere Merkmale sein, welche bereits bekannt sind, bevor der Keks entsteht. Mit dem richtigen Training sind die Gewichte dann so justiert, dass aus gegebenen Parametern jeweils die geschätzte Qualität berechnet wird, ohne genau zu wissen, welchen Einfluss welcher Parameter hat.
Bildverarbeitung mit Neuronalen Netzwerken
Neuronale Netzwerke zur Bildverarbeitung bilden eine ganz eigene Klasse. Da es sehr umständlich wäre, jedes Bild als Reihe von Pixeln aufzuspalten und dabei jeden Pixelwert als einen Eingangsparameter unseres Netzwerks zu nehmen. Zudem würde das Netzwerk riesig, bedenkt man eine heute eher geringer als übliche Auflösung von Full HD mit 1920 auf 1080 Pixeln. 2‘073‘600 Eingangsneuronen wären nötig, mit noch mehr Neuronen auf den jeweiligen Zwischenebenen. Bei so einem komplexen Gebilde wären auch mehr als zwei Zwischenebenen nötig. Ganz abgesehen davon würden bei der Aufspaltung des Bildes auf die jeweiligen Neuronen die räumlichen Zusammenhänge innerhalb vom Bild verloren gehen und damit wertvolle Information.
Die über Jahre entwickelten Convolutional Neural Networks (Faltendes Neuronales Netzwerk) zur Bildverarbeitung fanden 1989 ihren ersten Höhepunkt als es Yann LeCun und weiteren Forschern gelang, Bildern von Postleitzahlen automatisch mit einem trainierten Netzwerk auszuwerten. Die in diesen Netzwerken verwendeten Convolutions bezeichnen zu Deutsch Faltungen, was eine mathematische Gewichtung von Werten mit räumlichem Zusammenhang darstellt. Dabei wird ein Filter, welcher wie ein Bild Pixel mit einzelnen Werten hat, Schritt für Schritt über das Bild gelegt und mit den Pixelwerten des Bildes verrechnet. Die so entstehenden gewichteten Mittelwerte werden an die nächste Schicht weitergegeben. Die immer kleiner werdenden, gemittelten Bilder haben zum Schluss eine Auflösung von 1 x 1 Pixel. Diese können als Eingabeparameter für normale Neuronale Schichten eingesetzt werden, um zum Schluss bei einem einzigen Wert zu landen. Dieser könnte zum Beispiel die Qualität des Kekses, basierend auf dem Bild darstellen. Zum Trainieren der Gewichtungen der Faltungsfilter werden dem Netzwerk Bilder mit vorgegebener Qualität gezeigt. Durch die Fehlerrückführung können automatisch, ausgehend vom Qualitätswert, die optimalen Gewichtungen für die Faltungsfilter berechnet werden.
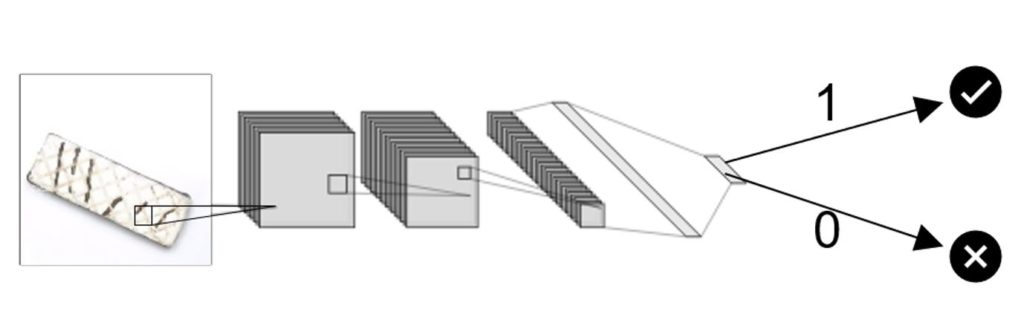
Verarbeitung eines Bildes mit einem Convolutional Neural Network zu einer Qualitätsbewertung (Klassifizierung).
Datensets
Damit Neuronale Netzwerke gut funktionieren, benötigen sie Unmengen an gelabelten Daten. Gelabelt heisst in unserem Beispiel, dass zu jedem Bild entsprechende Qualität bekannt ist. Da nicht für jedes spezifische Problem solche Mengen an Daten aufgezeichnet werden können, gibt es online Angebote an frei verfügbaren, gelabelten Datensets. Diese können verwendet werden, um die Netzwerke „vorzutrainieren“. Obwohl nicht auf den Zieldaten trainiert, sind diese vortrainierten Netzwerke einfacher und schneller auf den jeweiligen Task einzurichten, als wenn dies mit untrainierten gemacht wird. Eines der grössten und auch meistverwendeten Datensets ist die ImageNet Datenbank mit über 14 Millionen gelabelten Bildern in über 20‘000 Klassen.
Netzwerkarchitekturen
Aus den obigen zwei Basis-Beispielen von Neuronalen Netzwerken gibt es 100erte entwickelte Netzwerkarchitekturen. Jede Architektur verfolgt ein genaues Ziel und kann für einen bestimmten Analysefall verwendet werden. Wir beschränken uns in diesem Artikel nur auf die Netzwerke zur Bildanalyse. Auch dort gibt es genügend unterschiedliche Architekturen. Moderne Deep Learning Bibliotheken, welche in diversen Programmiersprachen vorhanden sind, bieten standardmässig aktuelle, vorgefertigte Netzwerke an, meistens mit der Option von vortrainierten Parametern. Im Folgenden gehen wir auf die einzelnen Unterkategorien von Netzwerken zur Bildverarbeitung ein.
Bildklassifizierung
Die Bildklassifizierung oder auch Bilderkennung bildet den Grundstein für alle weiteren Netzwerktypen. Es entspricht dem oben vorgestellten Netzwerk zur Erzeugung eines Zahlenwerts aus einem Bild. Die Zahlenwerte können einzelnen Klassen zugeordnet werden. So kann dieselbe Netzwerkarchitektur sowohl für die Unterscheidung von Hunde- und Katzenbildern, wie auch zur Klassifizierung der Qualität von Keksen verwendet werden. Die Bildklassifizierung wird vorwiegend für Bilder verwendet, bei denen nur ein Objekt zu sehen ist, wie bei unserem Keks auf dem Bild oben. Für die Bildklassifizierung sehr bekannt und gut erprobt sind die 2015 vorgestellten ResNet – Architekturen. Wir werden im zweiten Teil eine dieser Architekturen genauer anschauen.
Beispielarchitektur
Das für unseren Fall verwendete Netzwerk für die Klassifizierung der Kekse ist ein ResNet-18, das kleinste der ResNet Familie. Im Kern besteht das Netzwerk aus sich wiederholenden convolutional Blocks welche, wie der Name schon sagt, auf mehreren Faltungen mit erlernten Filtern basieren.
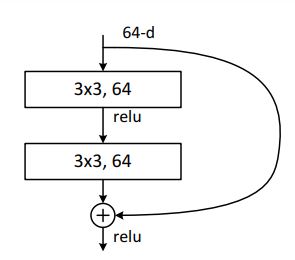
Detail eines Residual Blocks mit zwei Faltungselementen, der Skip-Connection und der ReLU (Rectified Linear Unit)-Aktivierungsfunktion.
Die Besonderheit bei der ResNet Architektur sind die skip-Connections, welche einzelne Blöcke durch entsprechende Gewichtungen umgehen können. Dies stabilisiert das Training und ermöglicht es dem Netzwerk, einzelne Features einfacher zu ignorieren.
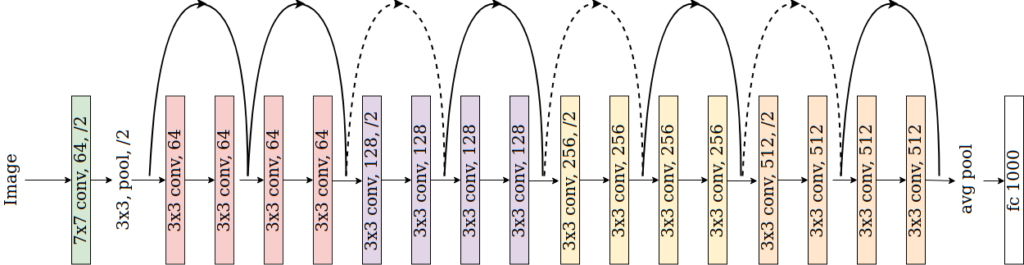
ResNet-18 Netzwerkarchitektur mit den convolutional Blocks welche durch die skip-Connections umgangen werden können.
Objekterkennung
Die Objekterkennung geht einen Schritt weiter. Bilder können nun mehrere verschiedene Objekte an unterschiedlichen Positionen innerhalb des Bildes enthalten. Die Netzwerke zur Objekterkennung können sowohl den Ort, wie auch die Klasse der Objekte bestimmen. Dazu wird in zwei Schritten gearbeitet, um einerseits mögliche Objekte ausfindig zu machen, und andererseits diese den richtigen Klassen zuzuordnen. Seit 2016 bleibt die Klasse von YOLO – Architekturen (You Only Look Once) Spitzenreiter für Objekterkennung. Moderne Umsetzungen dieser Netzwerke sind in der Lage, Filme in Echtzeit zu verarbeiten und auf jedem Frame eine Objekterkennung durchzuführen.
Bildsegmentierung
Noch weiter als die Bildklassifizierung bzw. Objekterkennung geht die Bildsegmentierung. Die Objekterkennung legt nur einen groben Rahmen um das klassifizierte Objekt, bei der Bildsegmentierung geschieht die Klassifizierung auf Pixelebene. So wird jedes Pixel des Objektes einer Klasse zugeordnet. Wird sogar jedes Pixel auf dem Bild klassifiziert, spricht man von semantischer Segmentierung. Werden nur die Objekte von Interesse genau eingegrenzt und klassifiziert spricht man von Instanzsegmentierung. Bezogen auf unseren Fall kann die Aufgabe entweder das pixelgenaue Erkennen und Klassifizieren von Keksen bedeuten, oder aber eine Segmentierung innerhalb jedes Kekses mit z.B. Regionen mit zu wenig, normal und zu viel Schokolade drauf. Netzwerke zur Bildsegmentierung beinhalten meist einen codierenden Teil (Verarbeitung von Bild zu einzelnen wenigen Zahlen) und einen Decodierenden, damit wieder ein Bild entsteht und jedes Pixel einer Klasse zugewiesen ist. 2015 wurde die U-Net Architektur für die Segmentierung von Zellen vorgestellt und wird bis heute in verschiedensten Bereichen rege verwendet.
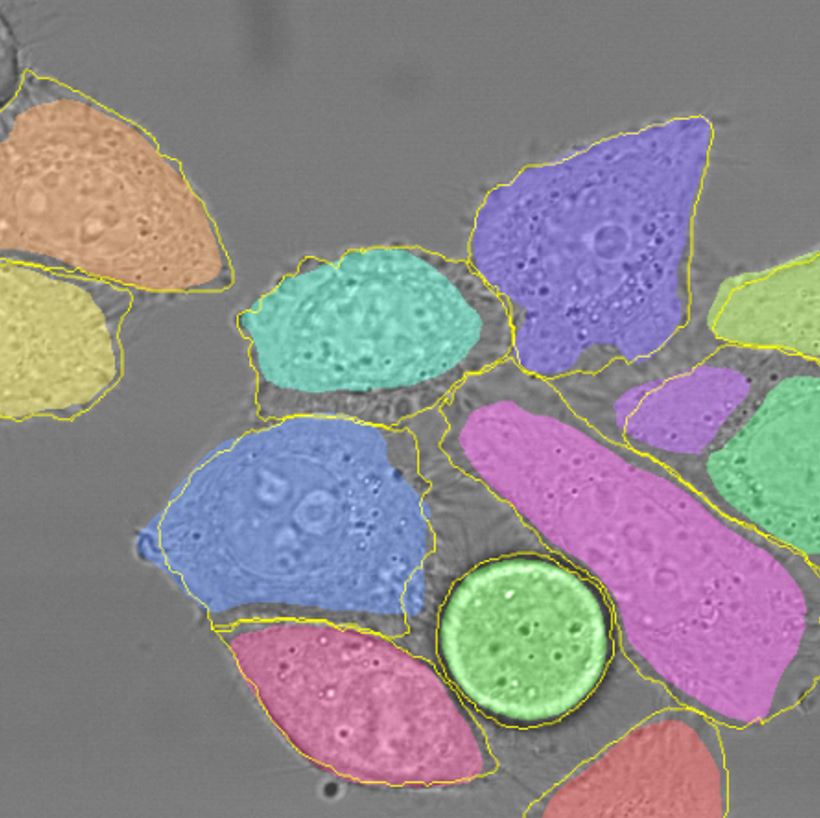
Bild von Segmentierten Zellen aus Olaf Ronneberger et. al 2015 “U-net architecture image segmentation”