In unserer Serie um industrielle Bildverarbeitung (Machine Vision) möchten wir die Werbetrommel für Deep Learning rühren. In diesem Blog möchte ich den Unterschied zwischen einem ‘klassischen’ und einem Deep Learning Ansatz in der Bildverarbeitung näher bringen.
Finde den QR-Code
In vielen Produktionsprozessen ist es wichtig, dass die Fabrikate getrackt und damit identifizierbar werden. Wer nicht gleich jedes Fabrikat mit einem RFID Chip versehen will, beschränkt sich meist auf einen Bar-, QR- oder Data Matrix-Code. Diese visuellen Codes müssen von einem Vision System erkannt und gelesen werden können. Das kann sehr einfach sein, wenn der Code immer genau an der gleichen Stelle im aufgenommenen Bild liegt. Ist dies nicht der Fall, benötigt es einen Algorithmus, der das Bild auf einen Code hin prüft.
Im Bild unten ist ein Beispiel eines QR Codes auf einem Gegenstand. Der Code selber ist auf dem Kopf und nicht schön horizontal ausgerichtet. Was für Regeln kämen Ihnen in den Sinn, die ein Computer ausführen müsste, damit er den QR Code auf dem Bild identifizieren kann? Keine einfache Aufgabe, denn die Regeln müssten nicht nur genau für dieses Bild gelten.

Grundsätzliches zur Bildverarbeitung
Um beim Beispiel zu bleiben, aber auch auf ein paar generelle Punkte hinzuweisen, hier ein paar Gedanken, wie man das Problem lösen könnte:
- Nicht relevante Information wird entweder nicht aufgezeichnet oder man streicht sie beim Preprocessing raus.
Die Farbe ist bei einem QR Code nicht relevant, nur der Kontrast. Es ist also einfacher das Bild nur schwarz-weiss zu betrachten und möglichst grossen Kontrast zu haben. Falls ein Bild aber eine schlechte Auflösung oder eine schlechte Belichtung hat, dann könnte der Kontrast nicht genügend hoch sein.
- Regeln implementieren, sodass sie möglichst jeden Fall abdecken.
In unserem Beispiel haben wir absichtlich einen QR Code auf dem Kopf gewählt, damit wir nicht Regeln festlegen, die dann in der Realität plötzlich nicht mehr anwendbar sind. Für eine Implementierung eines Vision Systems (das gilt übrigens für jegliche Softwareentwicklung) müssen vor allem auch die schwierigsten Fälle gesucht und der Algorithmus (das Regelwerk) darauf getestet und abgestimmt werden. Bei Machine Vision Systemen hat man allerdings einen Vorteil. Man kann durch cleveres Design des Bilderfassens gewisse schwierige Fälle erst gar nicht zulassen. Bei unserem Sackmesser könnte es zum Beispiel gar keine Bildaufnahme von QR Codes auf dem Kopf geben, wenn im Prozess vorher sichergestellt wird, dass sich nach dem Anbringen des Codes das Fabrikat nicht mehr drehen kann.
- Man macht sich die Invarianzen des zu identifizierenden Objektes zu Nutzen.
Das bedeutet bei einem QR Code konkret, dass er egal in welcher Farbe und Grösse, immer drei Eckpunkte hat, an denen man ihn erkennen kann. Der QR Code ist so designt, dass man ihn ohne grosse Mühe auf einem Bild erkennen kann. Daher funktioniert ein QR Code Scanner auf dem Smartphone auch so schnell und zuverlässig. Das Geheimnis liegt im Erkennungspattern 1:1:3:1:1 der Eckpunkte, dem leeren Rand (Quiet Zone) und weiteren Merkmalen. Für Neugierige gibt’s hier mehr dazu https://aishack.in/tutorials/scanning-qr-codes-1/.
Ein Mensch ohne Lesegerät kann mit QR Codes nichts anfangen. Daher gibt es nebst den Codes auch andere Informationen, welche auf ein Fabrikat gedruckt werden. Dies kann zum Beispiel eine Identifikationsnummer oder ein Mindesthaltbarkeitsdatum sein. Muss solch eine Information aus einem Bild extrahiert werden, spricht man von Optical Character Recognition (OCR).
regelbasiert vs. datenbasiert
Bis jetzt lagen wir in der Domäne der Vision Tasks ohne Einsatz von Deep Learning. OCR ist ein gutes Beispiel, um von regelbasierten (ohne Deep Learning) zu datenbasierten (mit Deep Learning) Ansätzen zu gelangen. OCR Lösungen gab es schon lange bevor Deep Learning bekannt war. Es gibt eine ganze Bandbreite an Problemen in OCR, zum Beispiel die Frage nach dem Text Standort in einem Bild, der Klassifizierung eines hand- oder maschinengeschriebenen Buchstabens oder das Erkennen ganzer Wörter und Texte. Mit in die Problematik spielt wie immer auch die Auflösung bzw. die Qualität der Bilder oder der Texte auf den Bildern.
Gehen wir aber von einem einfachen Setting aus, damit ich die regelbasierten Ansätze verdeutlichen kann. Wir haben ein Bild eines Wortes gegeben, das in Areal 14 pt geschrieben wurde.
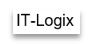
Das Ziel ist aus dem Bild oben den Text „IT-Logix“ zu erhalten. Dazu wird das Problem in Teilprobleme zerlegt, die dann gelöst werden können. Es ist so nicht schwierig, die einzelnen Buchstaben im Bild anhand von Regeln zu identifizieren.
- Da jedes schwarze Pixel zu einem Buchstaben gehört und die Buchstaben durch weisse Pixel abgetrennt sind, kann man einzelne Buchstaben gut identifizieren. (mit Ausnahme vom i-Punkt)
- Alle angrenzenden schwarzen Pixel bilden zusammen einen Buchstaben.
- Diesen dann zu identifizieren wird nicht sonderlich schwierig, da alle möglichen Buchstaben und ihre Form bekannt sind. Somit ist ein Abgleich mit einer Vorlage (Template Matching) einfach und jeder Buchstabe kann so erkannt werden.
Was ist aber mit einem handgeschriebenen Wort? Dort ist das Problem schon einiges schwieriger. Zum einen funktioniert das Eruieren von Buchstaben nicht mehr ganz so einfach, da bei einer Schrift die Buchstaben eventuell alle zusammenhängen könnten. Zum anderen sind Vorlagen von Buchstaben nicht brauchbar, da ein Buchstabe von Schrift zu Schrift sehr stark im Aussehen variiert (und bei den meisten sogar innerhalb eines Wortes).
Wie oben als Strategie beschrieben, sollte man sich die Invarianzen der Buchstaben zu Nutzen machen. Aber diese Invarianzen zu finden, ist gar nicht so einfach. Für den Buchstaben „o“ könnte so eine Invarianz über alle Schriften durch einen weissen Pixelbereich, der von einem schwarzen eingeschlossen wird, gegeben sein. Jedoch ist auch dies bei einigen Schriftbildern sicherlich nicht zutreffend. (siehe Abbildung)
Lassen wir die Maschine die Regeln definieren
Hier kommt Deep Learning ins Spiel. Lassen wir doch die Suche nach Invarianzen durch die Maschine erledigen. Sie können viel besser grosse Datenmengen von handgeschriebenen Texten durchgehen und Muster erkennen. Damit der Computer diese aber finden kann, muss er wissen, nach was er suchen soll. Im Beispiel muss eine Vielzahl an geschriebenen Wörtern als Bilder vorliegen und dazu auch die ‚übersetzte‘ Form (der Text, der auf dem Bild zu sehen ist). Mit Hilfe dieser kann ein Deep Learning Modell Invarianzen/Muster erkennen und gewissermassen Regeln definieren. Diese erlauben es, bei noch nicht ‚gesehenen‘ Daten die gewünschten Ergebnisse auszuspucken.
Untenstehend zwei Grafiken, welche den Unterschied zwischen dem klassischen Machine Vision und dem Deep Learning Ansatz aufzeigen.
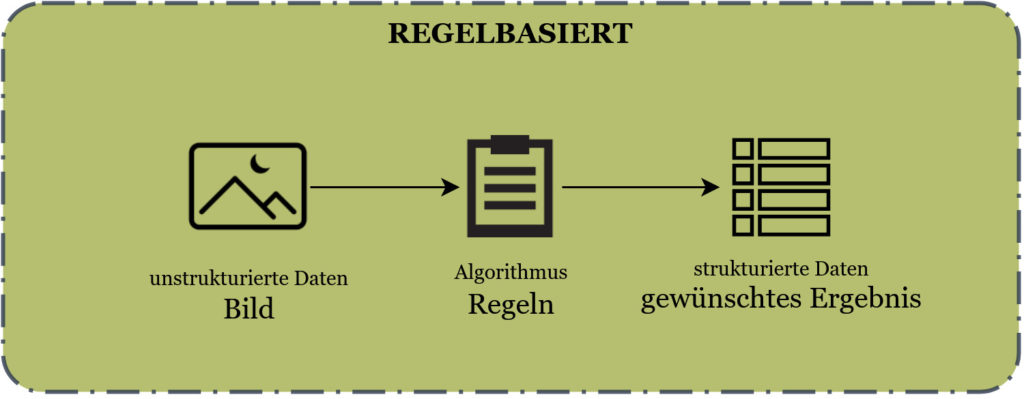
Im klassischen, oder auch regelbasierten Ansatz schreiben Programmierer Regeln, welche aus Bildern oder anderen unstrukturierten Daten (Textdateien, Präsentationen, Videos, Audiodaten, aufgezeichnete Sprache) strukturierte Daten in Form von Tabellen oder Informationen umwandeln, welche direkt für die Verarbeitung mit Computern geeignet ist.
Die gewünschten Ergebnisse sind beim einleitenden QR Code Problem zum Beispiel die Koordinaten des QR Codes auf dem Bild, die Ausrichtung oder aber auch der Inhalt des QR Codes. Bei OCR Problemen wäre das Ergebnis beispielsweise der erkannte Text oder die Lage des Textes auf dem Bild.
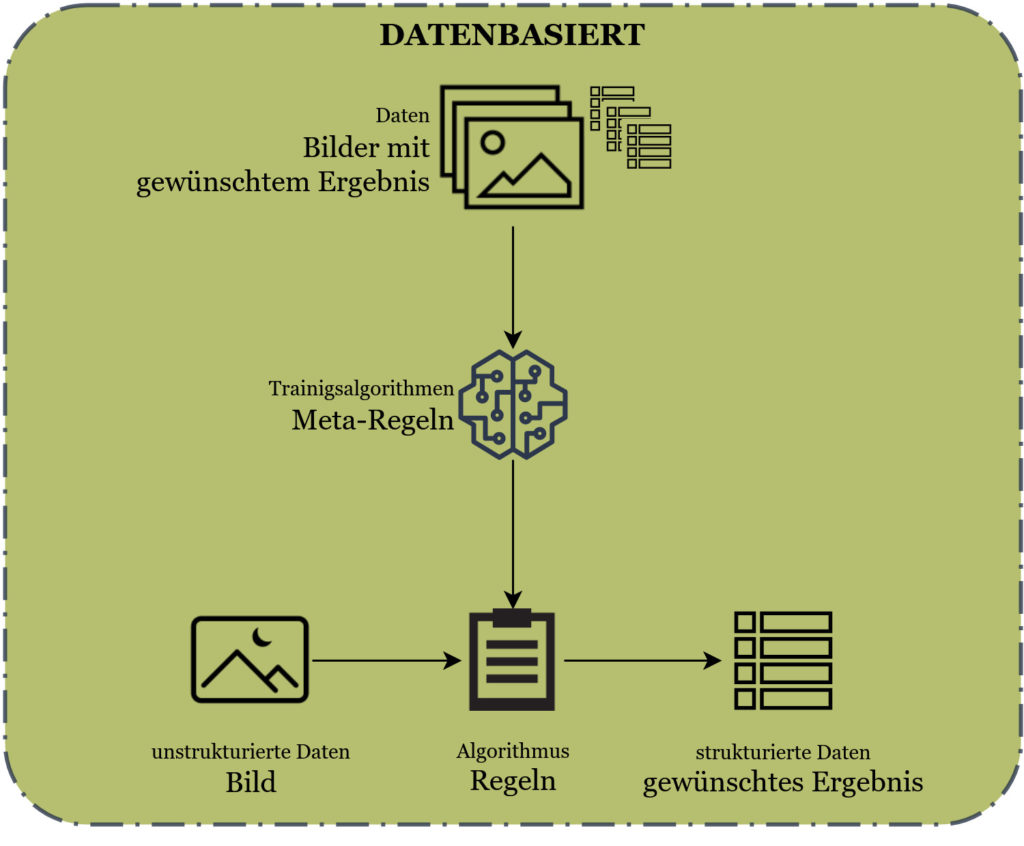
Werden nun die Programmierer in diesem Zusammenhang von Data Scientisten ersetzt und ein Deep Learning Ansatz gewählt, treten an die Stelle von implementierten Regeln trainierte Regeln. Damit dies funktionieren kann, müssen Datensätze vorliegen, die den Bezug zwischen den Bildern und den gewünschten Ergebnissen aufzeigen. Durch das Aufstellen von Meta-Regeln wird dann bestimmt, wie aus den Bilder-Ergebnis Paaren Muster erkannt und damit Regeln definiert werden.
Viele Regeln – viel Vergnügen!
Der Deep Learning Ansatz sieht in erster Linie komplizierter aus. In der Tat ist die Herangehensweise vielschichtiger und eignet sich auch nicht für jedes Bildverarbeitungsproblem. Doch wie beim OCR schon angetönt: Es ist in vielen Fällen schwierig oder gar unmöglich, Regeln selber zu definieren. Besonders in der Lebensmittelindustrie, wo Lebensmittel nie ein konstantes Aussehen haben, ist das regelbasierte Vorgehen sehr schwierig.
Weiter gilt es festzuhalten, dass sich einmal definierte Regeln/Algorithmen in der Praxis verändern müssen. Der Grund dafür ist, dass sich das Aussehen der Fabrikate durch Designanpassungen oder neue Produkte verändern kann. Ein von Hand gepflegtes Regelwerk ist bei vielen Regeln so komplex, dass eine Anpassung kein Vergnügen ist. Es ist daher erstrebenswert, dass bei einer Veränderung der Fabrikate das Regelwerk nicht immer wieder manuell angepasst und erweitert werden muss. In so einer Situation bietet sich ein Deep Learning Ansatz an, der durch das automatische Erstellen (trainieren) von Regeln mit solchen Problemen besser umgehen kann.