In meinen letzten beiden Blogs habe ich Ihnen einen Überblick zur Optimierung von BI / DWH Systemen [Link] gegeben und das Vorgehen zur Analyse von SAP Data Services Jobs [Link] beschrieben. In meinem heutigen Blog gehe ich bei der Optimierung von SAP Data Services Jobs nun weiter ins Detail, indem ich Ihnen die Top 4 Anti-Patterns beschreibe, wie sie mit Sicherheit Ihren SAP Data Services Server in die Knie zwingen werden.
Das Ping-Pong-Anti-Pattern Nr. 1 – Remote Function Calls
SAP Data Services ist ein Applikationsserver und ist in der Praxis selten auf demselben Server installiert, wie die Datenbank läuft. Falls die Daten innerhalb von SAP Data Services verarbeitet werden, sollte deshalb peinlichst genau darauf geachtet werden, dass die Daten immer als ganzes Datenset in den Applikationsserver eingelesen werden, da es sonst zu unnötigem Overhead kommt (z.B. erhöhter Netzwerkverkehr, erhöhte Anzahl DB-Verbindungen etc.). Oder anders formuliert: Man sollte das Lesen von einzelnen spezifischen Datensätzen oder Aufrufen von Datenbankfunktionen während der Ausführung eines Datenflusses wenn immer möglich vermeiden.
Dieses konkrete Anti-Pattern sieht illustrativ so aus:
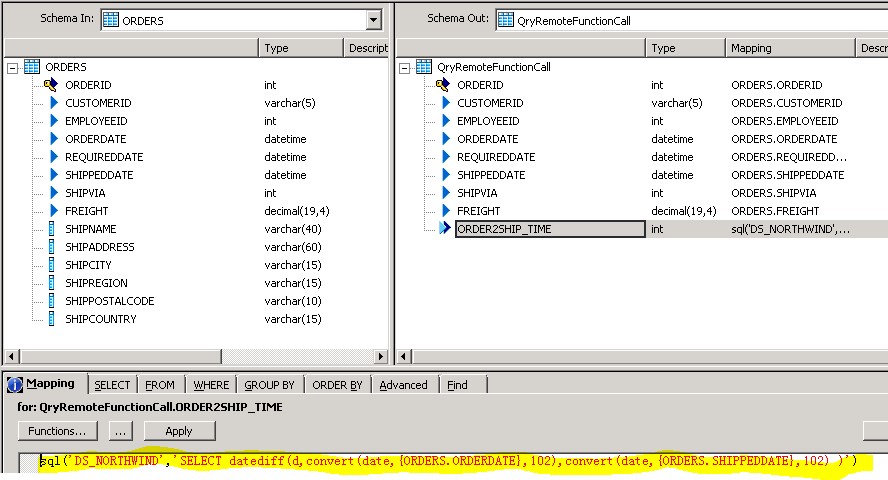
In diesem Beispiel wird innerhalb der Verarbeitung des Datenflusses die SQL Server Funktion datediff() parametrisiert aufgerufen (könnte auch ein ABAP Programm, ein TSQL, ein PL/SQL oder Ähnliches sein). Ist das so implementiert, führt SAP Data Services für jeden Datensatz einen Datenbank-Call aus, was bedeutet, dass für jeden Datensatz eine Datenbank- und eine Netzwerkoperation nötig ist. Somit muss für jeden Datensatz dieser eine Aufruf inkl. Erhalt des Resultatsets abgewartet werden und erst danach wird der nächste Datensatz verarbeitet.
Dieses Ping Pong Spiel kann sehr einfach verhindert werden, indem die Logik des SQL Aufrufs nach SAP Data Services in eine Data Services interne Funktion oder eine Custom Function verlagert wird. Dabei gilt es jedoch weiterhin darauf zu achten, dass in der Custom Function keine sql() und lookup() Funktionen verwendet werden. Dies würde wieder zu einem Ping Pong Spiel führen.
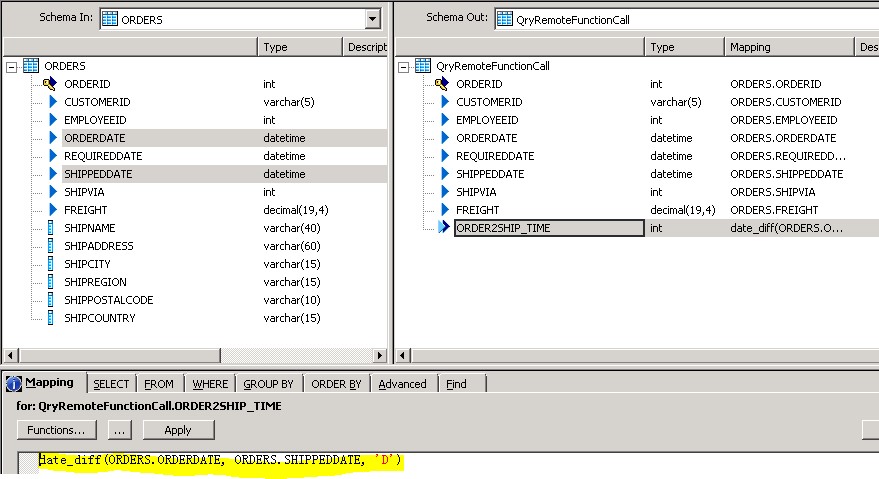
Im konkreten Beispiel sieht der Funktionsaufruf mittels SAP Data Services Bordmitteln so aus:
Beim Laufzeitvergleich der beiden Versionen sieht man den Unterschied sehr deutlich.
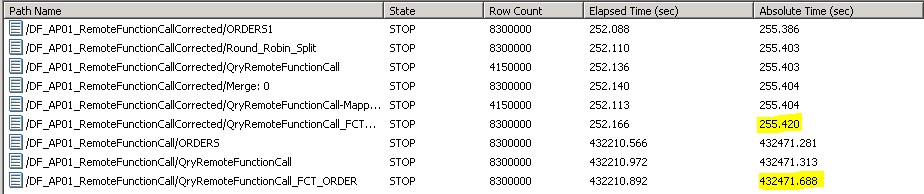
Die Version mit dem Anti-Pattern benötigt für 8.3 Mio. Datensätze 120h 8min und mit der korrekt implementierten Version 4min 12s. Dies entspricht einem Unterschied von 120h und 4min, was einer Performanceverbesserung um den Faktor 1696 entspricht.
Das Ping-Pong-Anti-Pattern Nr. 2 – No Cache Table calls
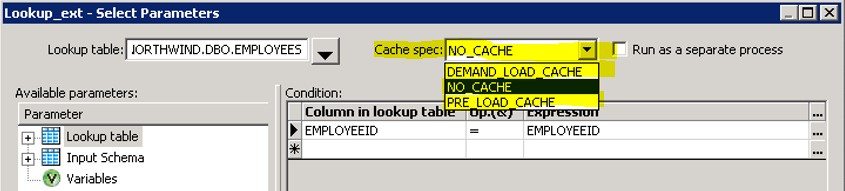
In SAP Data Services gibt es die Lookup_ext() Funktion und den Table Comparison Transform, womit man das Cache Verhalten beeinflussen kann.
Lookup_ext() Funktion:
Diese Funktion wird sehr oft benötigt, da sie sehr gut geeignet ist, um Datenfelder basierend auf einem Schlüsselfeld innerhalb des Datenflusses nachzuschlagen. Diese Funktion ist sehr oft einem Outerjoin vorzuziehen, da sie auch mit Quellduplikaten umgehen kann. Dabei stellt sie drei Cache Funktionen zur Verfügung:
- No Cache: Für jeden Datensatz wird ein Datenbank-Aufruf abgesetzt (analog Ping-Pong-Anti-Pattern 1).
- Demand Load Cache: Für jeden Schlüssel, der nachgeschlagen wird, wird ein Datenbank-Aufruf abgesetzt und danach im SAP Data Services Cache gehalten. Falls der Schlüssel in einem weiteren Datensatz auftaucht, werden die Werte aus dem SAP Data Services Cache zuerst durchsucht und verwendet. Erst wenn der SAP Data Services den Schlüsselwert nicht aufweist, wird ein weiterer Datenbank Aufruf nötig.
- Preload to Cache: Bei dieser Einstellung wird die gesamte Lookup Tabelle in den SAP Data Services Cache geladen und somit nur noch auf dem Applikationsserver bearbeitet.
Die No Cache Einstellung führt wieder zu einem Ping-Pong-Anti-Pattern und ist im Normalfall zu vermeiden. Folgende „Rule-of-thumb“ hat sich für die Verwendung der lookup_ext() Funktion durchgesetzt:

Teilweise gibt es Grenzfälle, welche der drei Cache Optionen performance-optimal ist. Dann gilt es die verschiedenen Cache-Optionen durchzutesten und die optimale Einstellung zu finden. Im Beispiel unten sieht man die Laufzeit der drei verschiedenen Cache Varianten im Vergleich.
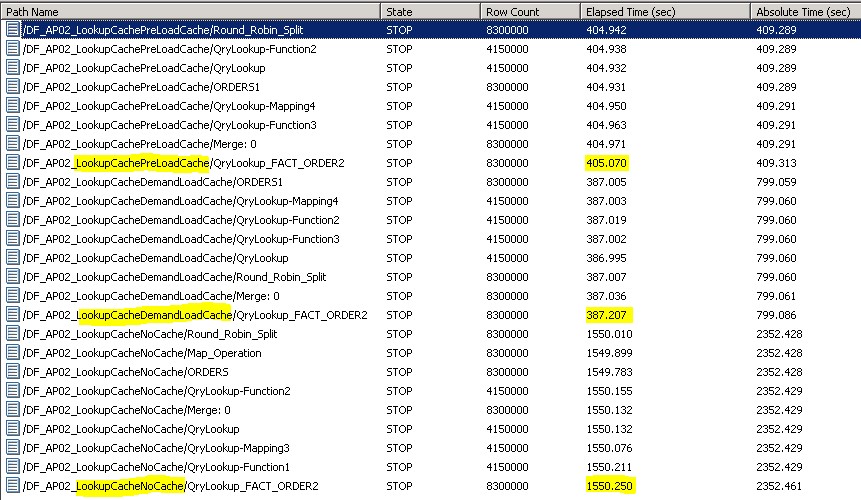
Preload to Cache benötigt für die 8.3Mio. Records 405s, Demand Load Cache 387s und No Cache 1550s. In diesem Beispiel ist die Demand Load Cache Funktion die optimalste Einstellung und gegenüber der No Cache Einstellung um den Faktor 4 schneller.
Table Comparison:
Der Table Comparison stellt sehr ähnliche Cache-Möglichkeiten zur Verfügung.
- Row-by-row select: Für jeden Datensatz wird ein Datenbank-Aufruf abgesetzt (analog Ping-Pong-Anti-Pattern 1).
- Cached comparison table: Hier wird die Vergleichstabelle vollständig in den SAP Data Services Server gelesen.
- Sorted Input: Hier wird vorausgesetzt, dass der Input im Query vor dem Table Comparison sortiert wird. Das Table Comparison Transform selektiert dann nur die Vergleichsrecords ab dem kleinsten Primary Key Schlüssel Wert.
![]()
Die Row-by-row Einstellung führt hier auch wieder, wie bei der No Cache Einstellung in der lookup_ext() Funktion, zu einem Ping-Pong-Anti-Pattern und ist im Normalfall zu vermeiden. Folgende „Rule-of-thumb“ hat sich für die Cache Einstellung beim Table Comparison durchgesetzt:

Das Alias-Anti-Pattern
Eines der am einfachsten zu lösenden Anti-Patterns ist die Nicht-Verwendung von Tabellen Aliasen. Verwendet man dieselbe Instanz einer Tabelle in mehreren Queries downstream, dann ist SAP Data Services nicht in der Lage, einen optimalen Ausführungsplan bzw. den SQL Push down korrekt zu erzeugen und der Datenfluss performed im Normalfall sehr schlecht.
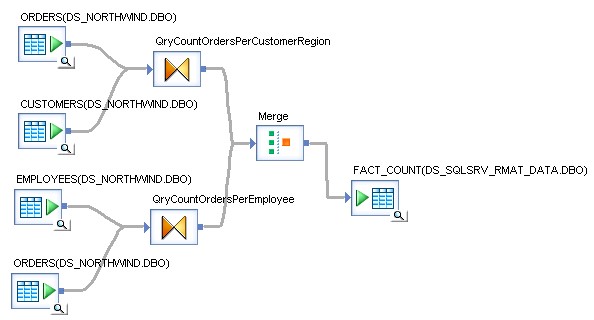
Im Bild unten sehen Sie einen Datenfluss, welcher keine Tabellen Aliase verwendet.
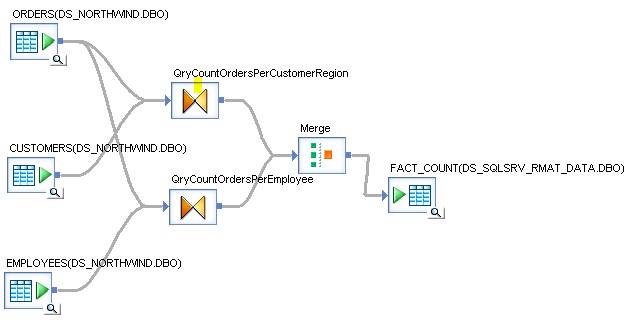
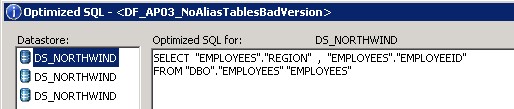
Das optimized SQL für diesen Datenfluss sieht wie folgt aus:
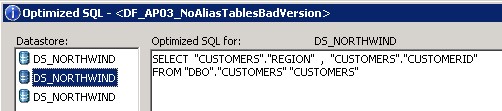

Eine bessere Version dieses Datenflusses sieht so aus:
Das optimized SQL für diesen Datenfluss sieht wie folgt aus:

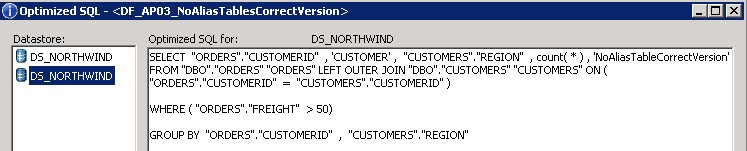
In diesem Beispiel erkennt man gut, wie sich das SQL verändert, wenn die Tabelle ORDERS 2x instanziiert wird. Im ersten Fall werden die gesamten 8.3 Mio. Records der Tabelle ORDERS, EMPLOYEES und CUSTOMERS in SAP Data Services eingelesen und das Group by und die Join Operation in der SAP Data Services Engine ausgeführt. In diesem Beispiel bedeutet dies konkret, dass 8.3Mio Datensätze von der DB gelesen, über das Netzwerk transferiert und in der SAP Data Services Engine verarbeitet werden müssen. Im zweiten Fall führt die Datenbank das Group by und die Join Operation aus und es wird nur noch das Resultat der Query an die SAP Data Services Engine übergeben. Dies bedeutet, dass anstatt 8.3 Mio. Datensätze nur 83 in der Data Services Engine verarbeitet werden müssen. Die Laufzeit verbessert sich dabei von 65 Sekunden auf weniger als eine Sekunde, was einem Faktor >65 entspricht.

Das Bulk-Load-Anti-Pattern
Immer wieder fällt mir auf, dass nur sehr wenigen Entwicklern bewusst ist, was der Unterschied zwischen dem „normalen“ Einfügen von Datensätzen über Insert Statements und dem Bulk Loader bedeutet. Fügt man Datensätze mittels Inserts Statements in die Datenbank ein, werden zur Laufzeit alle Constraints geprüft, die Indexe und das Transaction Log nachgeführt. Dies hat eine signifikante Reduktion der Ladeperformance gegenüber dem Bulk Loader zur Folge. Beim Bulk Load wird all das nicht geprüft bzw. nachgeführt. Beim Bulk Loader verhält sich jedes Datenbanksystem ein bisschen anders. So kümmert sich z.B. der Oracle API Bulk Loader selber darum, die Constraints und Indexe vor dem Bulk Load auszuschalten und nach dem Bulk Load wieder einzuschalten bzw. neu zu rechnen. Der SQL Server Bulk Loader funktioniert da etwas anders. Um beim SQL Server eine optimale Ladeperformance zu erzielen, sollte man die Datenbank im Recovery Modus „Bulk logged“ konfigurieren, dann die Constraints und Indexe vor dem Laden löschen und nach dem Laden wieder erstellen. Dies kann mittels Pre- und Post-Skript-Tasks erreicht werden. Aber Achtung: Wenn die Datenbank auf diese Weise konfiguriert ist, werden die Bulk Loads nicht geloggt und bei einem Datenbank Crash gehen alle Bulk Loads nach dem letzten Recovery Punkt verloren. Dies erfordert, dass man alle Jobs Restartable implementiert.
Im Bild unten sieht man das Target Tabellen Objekt und die 2 verschiedenen Einstellungen:


Zusammenfassung
Wie Sie sicherlich erkennen konnten, kann mit sehr einfachen Mitteln die Performance eines ETL Jobs massiv erhöht werden, wenn man gewisse Grundregeln in der Entwicklung einhält. Ich hoffe, dass ich Ihnen mit diesem Blog einige Probleme in Ihrer täglichen Arbeit mit SAP Data Services ersparen kann und freue mich auf Ihre Kommentare.