Im ersten Teil des Blogs wurde eine typische Ausgangslage vor der Operationalisierung einer Data Science Lösung beschrieben. Es wurden ausserdem die sich daraus ergebenden Ziele und Herausforderungen bei der Operationalisierung abgeleitet und der sog. Pilotbetrieb als Zwischenlösung vorgestellt.
Im diesem zweiten Teil des Blogs wird nun näher beschrieben wie der Pilotbetrieb pragmatisch implementiert werden kann und inwiefern er sich vom initialen Prototypen auf der einen Seite und vom späteren regulären Betrieb auf der anderen Seite abgrenzt.
Pilotbetrieb: 80/20-Regel
Um den Prototypen schnell in eine betriebsfähige Lösung mit möglichst wenig Aufwand zu überführen soll ein pragmatischer Ansatz nach der 80/20-Regel angewendet werden. Die Frage ist nun, welche der dem Prototyp fehlenden Funktionalitäten zwingend notwendig sind und auf welche verzichtet werden kann.
Die Antwort auf diese Frage hängt sicherlich stark von jeweiligen Situation des Unternehmens ab. Meistens werden aber Abstriche an der Funktionalität vorgenommen, indem bewusst IT-Standards des Unternehmens nicht implementiert werden. Die folgende Tabelle gibt einige Beispiele, wie sich der Pilotbetrieb gegenüber dem Prototyp auf der einen Seite, und dem regulären Betrieb auf der anderen Seite unterscheiden kann.

Automatisierung:
Der Data Scientist hat möglicherweise in seinem Prototyp eine Reihe von Skripten manuell angestossen. Zwischen den einzelnen Skriptaufrufen kann es Systembrüche geben, z.B. zwischen SQL, R, Spark o.ä. Diese Systembrüche hat er vielleicht durch Im- und Export von Zwischenergebnissen (z.B. via CSV-Dateien) überwunden.
Alle diese Schritte müssen im Pilotbetrieb automatisiert werden. Jeder einzelne Verarbeitungsschritt muss in einer Tabelle oder einer Datei gelogged werden. Der Job-Status sollte automatische kommuniziert werden (z.B. per Email oder auf einer Webseite). Jobs, die regelmässig laufen – z.B. täglich – sollten mit einem Scheduler eingeplant werden. Im Pilotbetrieb genügen dafür meistens die vom Betriebssystem mitgelieferten Scheduler wie cron oder der Windows Task Scheduler. Für die Automatisierung selbst reichen in der Regel moderne Skriptsprachen wie z.B. Python, wenn Tools aus den IT-Standards des Unternehmens nicht eingesetzt werden können (siehe unten). Bei der Auswahl der Skriptsprache sollte darauf geachtet werden, dass sie weit verbreitet ist und einen grosse Anzahl von unterstützten Modulen mitbringt, um z.B. Datenbank-Verbindungen aufzubauen, Emails zu verschicken, CSV-Dateien zu verarbeiten etc.
Im regulären Betrieb würde die Abteilung dagegen auf bereits existierende IT-Standards setzten: Prozess Engines, Workflow- oder ETL-Tools und die darin ebenso enthaltenen Scheduler. Möglicherweise wird auch ein dedizierter, unternehmensweiter Scheduler eingesetzt.
Selbstverständlich könnten solche IT-Standards und die damit verbundenen Tools auch von den Data Scientisten und IT-Spezialisten im Pilotbetrieb eingesetzt werden. Oft sind diese Mitarbeiter aber organisatorisch gar nicht in der IT-Abteilung eingegliedert und der Zugang zu dieser Infrastruktur ist schwer oder gar nicht möglich; evtl. ist der Zugang zu solchen Tools aber auch gar nicht von der IT-Abteilung gewünscht, um Nebeneffekte auf andere, produktive Prozesse zu vermeiden. Und selbst wenn der Zugang problemlos möglich wäre, könnte die Installation und Konfiguration der notwendigen Infrastruktur und die daran anschliessende Schulung für die Data Scientisten und IT-Spezialisten zu viel Zeit in Anspruch nehmen.
Generell kann man sagen, dass je mehr IT-Standards des Unternehmens eingesetzt werden, desto weniger lässt sich die 80/20-Regel anwenden. Wenn z.B. ETL- oder Workflow-Tools der IT eingesetzt werden, ist es durchaus nicht unüblich, dass Deployments aus diesen Tools heraus von anderen Prozessen oder Mitarbeitern durchgeführt werden und so an feste Releasezyklen gebunden sind, die für den Pilotbetrieb nicht akzeptable wären (siehe auch unten Release Mngmt / Deployment).
Andersherum gilt aber, dass je weniger IT-Standards eingesetzt werden, desto schneller und flexibler kann unter Umständen auf spezielle Wünsche der Fachabteilung während des Pilotbetriebes reagiert werden. Die Fachabteilung hat z.B. den Wunsch, dass fehlerhafte Eingabedaten im automatisierten Batchprozess in einer CSV-Datei mit den jeweiligen Fehlerbeschreibungen per Email zurückgeschickt werden. Bei den existierenden Tools der Unternehmens-IT-Standards müsste zunächst geschaut werden, ob so eine Funktionalität vorhanden ist, oder ob man die Tools erst entsprechend erweitern müsste. In diesem Fall müsste man evtl. mehrere Wochen oder gar Monate auf die Lösung warten.
So eine Funktionalität lässt sich aber mit einer modernen Skriptsprache recht schnell implementieren und in Produktion ausrollen (etwa innerhalb einer Woche). Gerade zu Beginn einer Data Science Lösung im Pilotbetrieb ist es wichtig, dass man auf Kundenanforderungen schnell reagieren und Prozesse schnell anpassen kann, um so die Akzeptanz und Transparenz der Lösung zu erhöhen.
Im Pilotbetrieb sollte es das Ziel sein, die Prozesse zwischen Empfang der Eingabedaten und Lieferung der Ausgabedaten voll zu automatisieren. Im gesamten Ende-zu-Ende-Prozess kann es aber doch noch manuelle Interaktionen geben. Es ist z.B. denkbar, dass die Ergebnisse der Lösung automatisiert in einer CSV-Datei an die Fachabteilung geschickt wird. Dort werden die Ergebnisse manuell von den Anwendern in einzelnen Prozessschritten berücksichtigt.
Es wäre aber auch denkbar, dass die Ergebnisse in einem täglichen Prozess per Dateitransfer an das operative System geschickt und dort importiert werden. Die Ergebnisse stehen dort in den Bearbeitungsmasken den Anwendern zur Verfügung. Bei einer solchen Lösung sind natürliche kleinere Anpassungen im operativen System notwendig.
Im regulären Betrieb würde aber vielleicht im operativen System ein Schaltknopf in der Bearbeitungsmaske implementiert werden, über den der Anwender in Echtzeit das Ergebnisse der Data Science Lösung abrufen kann. Das Abrufen der Daten würde im Hintergrund über ein Web-Service implementiert werden. Im regulären Betrieb wäre die Lösung somit voll automatisiert und würde auch noch die Ergebnisse in Echtzeit anzeigen, während sie im Pilotbetrieb die Ergebnisse z.B. täglich oder wöchentlich produzieren würde.
Support:
In der Regel leistet der Data Scientist alleine während der Entwicklung des Prototypen Support, sofern er in dieser Phase überhaupt schon Kontakt zu Abnehmern oder Anwendern hat.
Im Pilotbetrieb sollte der Data Scientist immer noch Support leisten, um inhaltliche Fragen oder Probleme zu den von ihm entwickelten Algorithmen zu lösen. Mindestens genauso wichtig ist aber der Support der Mitarbeiter, die die Data Science Lösung operationalisiert haben. Hier geht es um Fragen der operativen Prozesse. Es ist wichtig, dass die Entwickler der Operationalisierung und der Data Scientist und keine dritten Personen direkt Support leisten, damit Probleme so schnell wie möglich gelöst werden können. Dieses Team sollte nicht aus mehr als zwei bis drei Personen bestehen. Üblicherweise wird der Support auf Best-Effort Basis geleistet.
Im regulären Betrieb würde der First-Level Support ggf. über den User Help Desk oder den Support der operativen Systeme geleistet werden. Diese Mitarbeiter müssten evtl. noch entsprechend geschult werden. Die Data Science Lösung würde vielleicht auch noch an das Incident Management System angebunden, damit die Support Mitarbeiter dort die relevanten Informationen verarbeiten können. Im regulären Betrieb gibt es ausserdem oft definierte SLA’s, die über den Support zu Bürozeiten hinausgehen können.
Vielleicht ändern sich durch die Data Science Lösung im regulären Betrieb auch so viele Prozesse im operativen System, sodass hier Anwenderschulungen erforderlich sind.
Release Management / Deployment:
Während der Entwicklung des Prototypen gibt es wahrscheinlich noch kein Release Management und eine damit verbundene kontrollierte Ausrollung der Lösung von der Entwicklungs/Test-Umgebung in die produktive Umgebung. Evtl. ist in dieser Phase auch nicht einmal eine Trennung zwischen Entwicklung/Test und Produktion vorhanden. Im Prototyp wurden dann Änderungen ad hoc entwickelt und waren damit sofort ausgerollt. Allfällige Fehler müssten so ggf. aufwändig zurückgerollt werden.
Im Pilotbetrieb ist es zwingend notwendig mindestens zwei Umgebungen einzuführen: Entwicklung und Produktion. Änderungen werden nur noch ad hoc in der Entwicklungsumgebung entwickelt und dort zusammen mit allen anderen Anpassungen in einem Release getestet. Damit muss mindestens ein einfaches Release Management eingeführt werden. Im einfachsten Fall sind das Branches im Versionssystem, die mit der entspr. Versionsnummer gekennzeichnet werden. Das Deployment aus dem Branch der Version könnte theoretisch durch automatisierte Prozesse unterstützt werden. Die Entwicklung solcher Prozesse ist aber oft mit höherem Aufwand verbunden, sodass ein halb-automatischer Deployment-Prozess im Pilotbetrieb durchaus möglich ist. Wichtig ist vielmehr, dass dieser Prozess mit Guidelines gut dokumentiert ist, sodass das Risiko manueller Fehler minimiert wird.
Im regulären Betrieb kann es dagegen IT-Standards bzgl. Release Management geben, um so automatisierte und möglichst sichere Deployments zu ermöglichen. Diese Deployments werden dann in einigen Unternehmen von darauf spezialisierten Teams durchgeführt. Es kann allerdings sein, dass deswegen die Frequenz der Releases fest vorgegeben ist, z.B. einmal pro Quartal.
Zu Beginn des Pilotbetriebes werden aber flexible und kurzfristige Releasezyklen benötigt, damit schnell Verbesserungen und Problemlösungen ausgerollt werden können. Dies ist wiederum notwendig um bereits zu Beginn der Data Science Lösung eine hohe Akzeptanz bei den Anwendern zu schaffen.
Change Management:
Das Change Management ist eng mit dem Release Management verbunden. Während im Prototyp die Änderungen vielleicht noch ad hoc und ohne weitere Kommunikation vorgenommen wurden, sollte dieser Prozess im Pilotbetrieb besser kontrolliert werden: pro Release sollte transparent dargestellt werden, welche Änderungen vorgenommen werden und welche Auswirkungen diese auf Satelliten-Systeme haben können. Die Anwender und Support-Mitarbeiter dieser Systeme müssen wissen, wann welche Anpassungen zu erwarten sind. Sie müssen auch in der Lage sein, die Auswirkungen auf ihre Systeme im Rahmen des Releases in ihrer Testumgebung zu testen.
Allerdings sollten die Prozesse zum Change Management möglichst einfach sein, z.B. wöchentliche oder monatliche Absprachen mit allen Beteiligten um den Umfang des geplanten Releases zu besprechen. Die Ergebnisse der Absprachen und Priorisierungen können in einfachen Listen auf dem Netzlaufwerk oder in einer Webseite kommuniziert werden.
Im regulären Betrieb kann es Unternehmens-IT-Standards geben, die auch den Change Management Prozess regeln, z.B. ITIL. Hier werden Anpassungen in der Regel durch ein oder mehrere Steuerungsgremien diskutiert, bewertet, priorisiert und genehmigt. Dazu müssen die Aufwände der Änderungen geschätzt, die Finanzierung gesichert und anschliessende die einzusetzenden Ressourcen eingeplant werden. Die Change Management Prozesse im regulären Betrieb haben das primäre Ziel, langfristig sichere und kostendeckende Anpassungen in operativen Systemen sicherzustellen. Kurzfristige und flexible Anpassungen in der Anfangsphase des Pilotbetriebes lassen sich damit aber nicht erzielen.
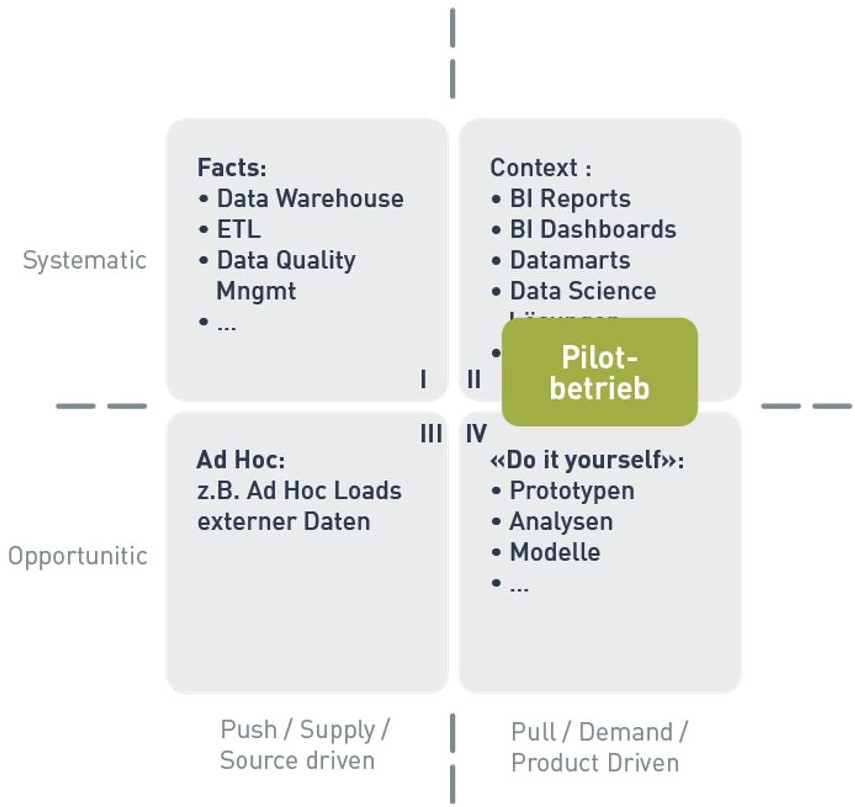
Im ersten Teil dieses Blogs wurde das 4-Quadranten Modell von Robert Damhof benutzt, um Ausgangslage und Zielsituation bei der Operationalisierung der Data Science Lösung zu beschreiben. Wenn nun also die meisten der Anforderungen an den Pilotbetrieb nach der 80/20-Regel implementiert wurden, könnte man das bildlich im 4-Quadranten Modell so darstellen, dass der Pilotbetrieb grösstenteils im Quadrant II liegt. Einzelne manuelle Aktivitäten – z.B. in den Anwenderprozessen oder im Deployment-Verfahren sind dagegen noch im Quadrant IV. In einem regulären Betrieb sollten dagegen alle Prozesse komplett im Quadrant II liegen.
Erfahrungen mit dem Pilotbetrieb
Der Pilotbetrieb wird in der hier umschriebenen Form seit ca. zwei Jahren von der IT-Logix AG bei einem ihrer Kunden durchgeführt. Dabei wurden vier Data Science Lösungen in den Pilotbetrieb überführt und laufen heute operativ in Produktion. Die erste der vier Data Science Lösungen lief ca. 10 Monate im Pilotbetrieb und wurde danach erfolgreich an die IT-Abteilung übergeben, die diese Lösung für den regulären Betrieb anpasste. Die zu Beginn des Pilotbetriebes erarbeitete fachliche Dokumentation diente bei der Übergabe an die IT-Abteilung als Spezifikation.
Die Automatisierung wird mit Python Skripten erzielt, die wiederum Algorithmen der Data Science Lösung in SQL, Hadoop oder R aufrufen.
In Python Modulen wurde Funktionalität für die Jobsteuerung, Logging, Emails, Im- und Export von Daten etc. implementiert. Diese Funktionalitäten sind generisch, d.h. sie können von allen Data Science Lösungen genutzt werden. Das so entstandene Framework wird ständig weiterentwickelt und erlaubt es heute Data Science Lösungen immer schneller in den Pilotbetrieb zu überführen: während die erste Data Science Lösung in ca. 3 Monaten in den Pilotbetrieb überführt wurde, können neue Data Science Lösungen heute in der Regel in weniger als 4 Wochen in den Pilotbetrieb überführt werden (Abhängigkeiten zu anderen Satellitensystemen können natürlich immer noch zu längeren Einführungsphasen führen).
Der Support wird grundsätzlich in allen Data Science Lösungen auf Best-Effort Basis geleistet. Es hat sich gezeigt, dass die Python-Skripte eine sehr hohe Stabilität haben, sodass der Support sich meistens auf Probleme mit fehlenden, oder falsch manuell aufbereiteten Eingabe-Daten beschränkt.
Generell konnte festgestellt werden, dass die Fachabteilungen eine flexible und schnelle Anpassungen an ihre Bedürfnisse sehr schätzen und auch dadurch die Data Science Lösung eine hohe Akzeptanz erfahren hat. Auf der anderen Seite zeigte sich die Fachabteilung sehr flexible in der Anpassung ihrer eigenen Arbeitsprozesse, damit die Data Science Lösung überhaut operativ genutzt werden konnte.
Der Pilotbetrieb wurde bei diesem Kunden eingeführt, weil die IT-Abteilung mangels Ressourcen die erste Data Science Lösung nicht in absehbarer Zeit in den regulären Betrieb übernehmen konnte. Nachdem weitere Lösungen erfolgreich in den Pilotbetrieb überführt wurden, kamen Befürchtungen auf, dass ausserhalb der IT-Abteilung eine sog. «Schatten-IT» entstehen könnte. Dieses wiederum erhöhte in gewisser Weise den Druck auf die IT-Abteilung weitere Data Science Lösungen vom Pilotbetrieb in den regulären Betrieb zu überführen. Letztendlich wird aber so der temporäre Charakter von Data Science Lösungen im Pilotbetrieb untermauert.
Grundsätzlich sollte die IT-Abteilung bei der Einführung des Pilotbetriebes involviert sein. Denn auch im Pilotbetrieb leistet sie wichtige Infrastruktur-Services wie Betriebs-, Datenbank-, Data Warehouse- oder Hadoop-Dienste. Ein Pilotbetrieb ist ohne Übereinkunft mit der IT-Abteilung nicht möglich.