Die Arbeit von Data Scientisten und Analysten ähnelt der Arbeitsweise von Forschern: sie versuchen Algorithmen und damit Lösungen zu finden, die aus den Daten Ihres Unternehmens einen Mehrwert erschaffen können, z.B. durch personalisiertes Marketing. Es ist aber nicht die Aufgabe und in der Regel auch nicht Teil der Jobbeschreibung eines Data Scientisten, solche Lösungen in ein Produkt oder eine operative Lösung zu überführen. Wenn die Stakeholder aber von der Lösung überzeugt sind, gilt es diese möglichst schnell und effizient zu operationalisieren. In vielen Fällen dauert der offizielle Weg, z.B. über ein Projekt in der IT-Abteilung zu lange.
In diesem zweiteiligen Blog wird beschrieben, wie man trotzdem die Lösung möglichst schnell und stabil in den produktiven Betrieb überführen kann. Im ersten Teil des Blogs wird eine typische Ausgangslage vor der Operationalisierung einer Data Science Lösung beschrieben. Es werden ausserdem die sich daraus ergebenden Ziele und Herausforderungen bei der Operationalisierung abgeleitet und der sog. Pilotbetrieb als Zwischenlösung vorgestellt. Im zweiten Teil des Blogs wird näher beschrieben wie dieser Pilotbetrieb pragmatisch implementiert werden kann und inwiefern er sich vom späteren regulären Betrieb unterscheidet.
Die Ausgangslage
Oftmals stellt sich die Ausgangslage vor der Operationalisierung der Data Science Lösung so oder so ähnlich dar:
- Prototyp: der Data Scientist hat einen Algorithmus in Form eines Prototypen entwickelt. Dieser Prototyp besteht vielleicht aus einer Ansammlung von Skripten in R, Spark, SQL o.ä. Diese Skripte sind auf der Workstation des Data Scientisten abgelegt. Um Ergebnisse der Lösung zu erzielen, werden die Skripte manuell angestossen. Eingabedaten und Laufzeitparameter werden vorher mehr oder weniger manuell aufbereitet.

Die Implementierung des Prototypen wurde über ein nicht projekt-gebundes Budget für alle Data Science Aktivitäten im Unternehmen finanziert. Die Data Scientisten des Unternehmens sind organisatorisch auch nicht der IT-Abteilung zugeordnet, sondern z.B. einer Stabsabteilung.
- Keine Spezifikation oder Dokumentation: der Prototyp ist nicht dokumentiert. Ebenso gibt es keine Spezifikation der Fachabteilung. Das ist in der Regel auch kaum möglich, weil die Fachabteilung allenfalls in wenigen Sätzen ein Problem formulieren, aber nicht den potentiellen Lösungsweg skizzieren kann. Ob es für dieses Problem überhaupt eine Lösung gibt, sollte der Data Scientist ja gerade im Rahmen seiner Forschungsarbeit herausfinden.
- Mehrwert: mit dem Prototypen konnte eine potentielle Lösung des Problems und damit der potentielle Mehrwert aufgezeigt werden.
- Auftrag zur Operationalisierung: die Stakeholder sind überzeugt von der Lösung und beauftragen, dass die Lösung in den regulären Betrieb überführt wird.
Ziele und Herausforderungen der Operationalisierung
Was bedeutet Operationalisierung in diesem Zusammenhang? Es bedeutet, dass manuelle Prozesse im Prototypen automatisiert werden und regelmässig in einem stabilen Betrieb in der Produktionsumgebung laufen. Quell- und Zielsysteme müssen über automatisierte Interfaces angebunden werden. Dafür sind ggf. auch Anpassungen in diesen Satellitensystemen erforderlich.
Um die eigene Ausgangslage und die Ziel-Situation besser zu verstehen hat sich das 4-Quadranten Modell von Robert Damhof bewährt. Die hier beschriebene Ausgangslage befindet sich hauptsächlich im Quadranten IV: hier werden spezielle Kundenanfragen implementiert; mehrheitlich aber nicht in einem systematischen Prozess, sondern eher ad hoc oder „opportunistisch“. Dabei bedienen sich die Data Scientisten in der Regel von Services in den anderen Quadranten, z.B. im Data Warehouse (Quadrant I).
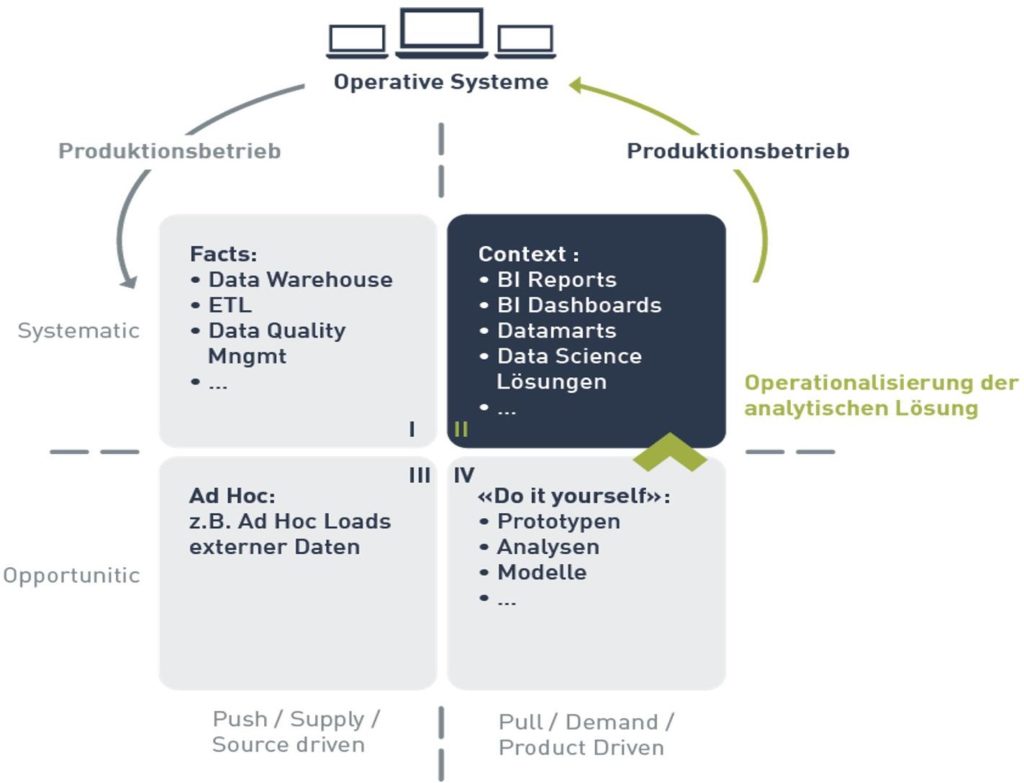
Die Herausforderung besteht nun darin, den im Quadrant IV entwickelten Prototypen in eine systematische, weitgehend automatisierte und betriebsfähige Lösung in Quadrant II zu überführen. Diese Aufgabe ist mit der „Operationalisierung von Data Science Lösungen“ gemeint.
In unserer exemplarischen Ausgangslage geht nun der Auftrag der Stakeholder zur Operationalisierung der Lösung an die IT-Abteilung. Dort gibt es für die Data Science Lösung bisher noch gar kein Projekt. Das bedeutet, dass hier erst ein Projekt initiiert werden muss, inklusive sämtlicher Projekt Management Aufgaben wie Projektplanung und –controlling, Aufwandschätzung, Genehmigung von Projektphasen und -ressourcen etc.
Bevor die IT-Abteilung dieses Projekt nun initiiert hat, kann sie noch gar keine potentiellen Aufwände und Kosten schätzen. Aus der Erfahrung bisheriger Projekte kann sie aber grob abschätzen, dass eine Implementierung nicht innerhalb des nächsten Jahres möglich ist.
Für die Stakeholder ist es zunächst schwer zu verstehen, warum der Weg vom Prototypen bis zur Lösung im regulären Betrieb (also der Weg von Quadrant IV nach Quadrant II) so lange dauern soll. Schliesslich ist aus ihrer Sicht der Grossteil der Lösung bereits implementiert. Ausserdem ist es für sie nicht akzeptabel, dass nun ein Jahr oder mehr auf die fertige Lösung gewartet werden muss. Es wird befürchtet, dass sich in dieser Zeit so viele Rahmenbedingungen geändert haben können, dass die heute gefundene Lösung dann nur noch teilweise valide ist.
Grundsätzlich kann in solchen Momenten die Frage aufkommen, warum sich ein Unterhemen Data Science Projekte leistet, wenn es anschliessend nicht möglich zu sein scheint, deren Ergebnisse zeitnah in Mehrwert im regulären Betrieb zu überführen.
Pilotbetrieb als Zwischenlösung
Ein Ausweg aus dieser Situation kann ein sog. Pilotbetrieb als Zwischenlösung sein. Damit ist gemeint, dass der Betrieb der Data Science Lösung für eine Zwischenzeit von der Abteilung geleistet wird, die den Prototyp erstellt hat, also der Abteilung der Data Scientisten. Dieser Pilotbetrieb soll solange gewährleistet werden bis die IT-Abteilung die notwendigen Ressourcen und Vorbedingungen geschaffen hat um die Data Science Lösung in den regulären Betrieb zu überführen.
Selbstverständlich kann auch im Pilotbetrieb der Prototyp im oben beschrieben Zustand nicht operativ betrieben werden. Die Aufwände für die manuellen Prozesse sind in der Regel zu hoch. Einige wichtige und grundsätzliche Voraussetzungen für einen stabilen Betrieb fehlen dem Prototypen. Dennoch ist es oft möglich, diese Lücken über einen bewusst pragmatischen Ansatz in relativ kurzer Zeit zu füllen, um den Pilotbetrieb zu starten – etwa in einigen Wochen bis zu drei Monaten.
Dieser pragmatische Ansatz besteht im Kern daraus, dass die sog. 80/20-Regel angewendet wird: es werden nur die wichtigsten benötigten Funktionalitäten mit weit weniger Aufwand implementiert, als wenn 100% der Funktionalitäten implementiert würden. Abstriche in der Funktionalität sind meistens möglich, indem IT-Standards des Unternehmens nicht berücksichtigt werden. Auf diese wiederum kann oft verzichtet werden, weil der Pilotbetrieb eine zeitliche Zwischenlösung ist.
Um den Prototyp des Data Scientisten für den Pilotbetrieb betriebsfähig zu machen bedarf es aber der Unterstützung von IT-Spezialisten (üblicherweise sind Data Scientisten keine IT-Spezialisten und umgekehrt).

Pilotbetrieb: Anforderungen
Welche Funktionalität fehlt dem Prototyp überhaupt gegenüber einer betriebsfähigen Lösung? Diese Frage lässt sich beantworten, indem man bekannte Methoden und Praktiken aus dem Application Lifecycle Management berücksichtigt:
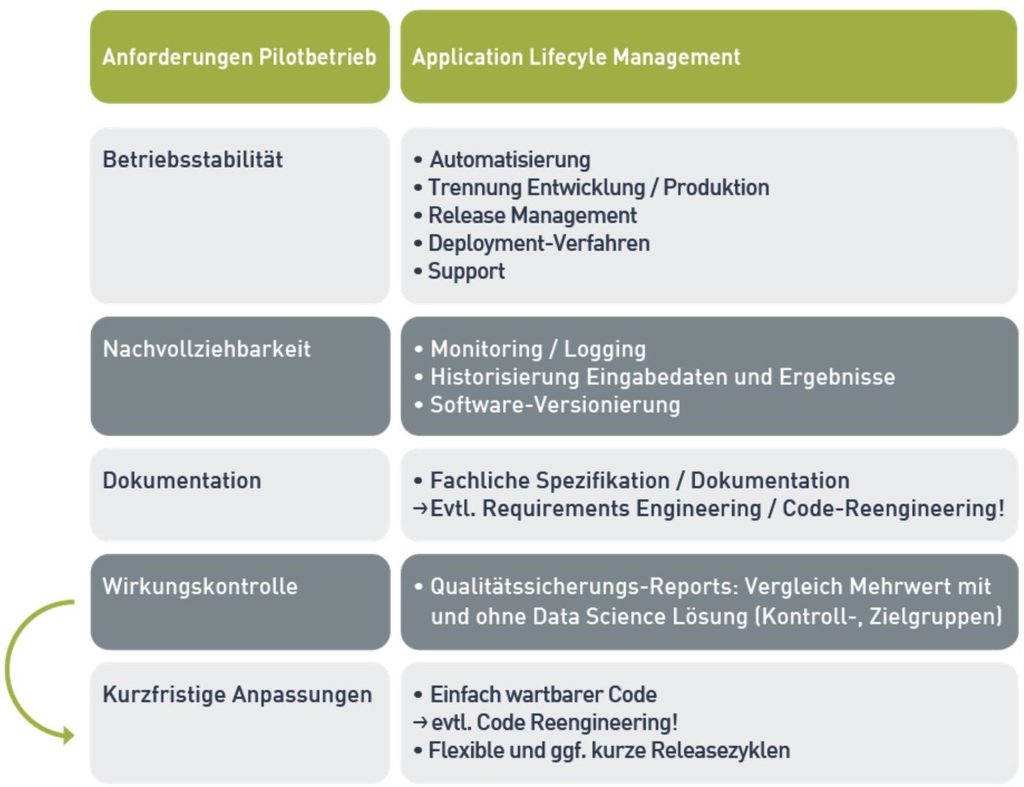
Betriebsstabilität:
Um mögliche manuelle Fehler zu vermeiden müssen manuelle Prozesse im Prototyp automatisiert werden. Als Seiteneffekt werden natürlich auch manuelle Aufwände im Betrieb minimiert.
Oft gibt es im Prototypen gar keine Unterscheidung zwischen Entwicklungs-, Test- und Produktionsumgebung. Diese ist aber zwingend notwendig, damit Weiterentwicklungen nicht in der Produktionsumgebung stattfinden und dort ggf. zu Fehlern führen. Durch diese Trennung werden auch ein Release Management und Deployment-Verfahren notwendig, um Weiterentwicklungen sicher und geordnet von der Entwicklungs- oder Test- in die Produktionsumgebung zu überführen. Möglicherweise sind in Codestrecken sogar Referenzen auf Datenobjekte fest auf eine der Umgebungen kodiert. Die Codestrecken müssen von solchen hart kodierten Referenzen entkoppelt werden, damit während des Deployments der Code ohne Anpassung von einer Umgebung in die andere transportiert werden kann.
Selbstverständlich benötigen die Anwender auch in der Phase des Pilotbetriebes Support, um Probleme zu lösen oder Fragen zu beantworten.
Nachvollziehbarkeit:
In der Regel muss man jederzeit nachvollziehen können wann welche Ergebnisse mit welchen Eingabedaten und mit welchem Algorithmus erzielt wurden. Diese Notwendigkeit kann aus internen oder externen Vorgaben resultieren (z.B. ISO 9001). Sie kann aber auch für die Optimierung der eigenen Prozesse hilfreich sein.
Dafür müssen die einzelnen Schritte bei der Jobausführung der Lösung gelogged werden. Diese Informationen und der Status der Jobausführung müssen in einem Monitoring-System einsehbar sein.
Eingabedaten und –parameter und die generierten Ergebnisse müssen archiviert werden. Ebenso wird eine Software-Versionierung benötigt, damit man nachvollziehen kann mit welcher Version der Software welche Ergebnisse in der Vergangenheit erzielt wurden.
Dokumentation:
Die implementierte Lösung sollte dokumentiert werden. Ähnlich wie bei der Nachvollziehbarkeit kann dieses eine Anforderung aus internen oder externen Vorgaben sein. In diesem Zusammenhang ist hier aber wichtiger, dass die implementierte Lösung transparent gegenüber den Anwendern ist. Damit ist weniger der vom Data Scientisten entwickelte Algorithmus gemeint, sondern vielmehr fachliche Rahmenparameter, wie z.B.:
- Welche Kundensegmente werden berücksichtigt?
- Welche geografischen Regionen werden berücksichtigt?
- Welche Angebotsarten werden berücksichtigt?
- Wann und in welcher Frequenz läuft der Job?
Oft wurden diese Fragen bereits während der Entwicklung des Prototypen mit der Fachabteilung besprochen, aber sie wurden nicht dokumentiert. Diese Rahmenparameter sind aber evtl. im Prototypen kodiert. Das bedeutet, dass ggf. ein Code Re-Engineering durchgeführt werden muss, um diese Parameter zu extrahieren und dokumentieren.
Es ist schliesslich zwingend notwendig solche Parameter zu dokumentieren und der Fachabteilung zur Genehmigung vorzulegen. Es ist nämlich möglich, dass während der Entwicklung des Prototypen andere Voraussetzungen galten als später im Pilotbetrieb. Denkbar ist auch, dass einige Parameter im Prototypen schlicht zur Vereinfachung oder Beschleunigung des Algorithmus gesetzt wurden, ohne diese mit der Fachabteilung abzusprechen.
Im Zusammenhang mit dem Pilotbetrieb hat die Dokumentation noch eine andere wichtige Funktion: bei der später geplanten Überführung vom Pilotbetrieb in den regulären Betrieb dient die Dokumentation dann als Spezifikation für die IT-Abteilung.
Wirkungskontrolle:
In produktiven Data Science Lösungen gibt es oft eine Wirkungskontrolle, mit der der Mehrwert der Lösung gemessen wird. Dabei wird meistens die Data Science Lösung auf eine Zielgruppe von Kunden angewendet, während die Kontrollgruppe der Kunden diese Lösung nicht erfährt. Durch Vergleich von KPIs der Ziel- und Kontrollgruppe kann so der Mehrwert gemessen werden, z.B. der Mehrumsatz.
Die Funktonalität der Wirkungskontrolle ist möglicherweise noch nicht im Prototyp implementiert. Evtl. müssen auch noch BI-Reports für die Ergebnisse der Wirkungskontrollen entwickelt werden.
Die Ergebnisse der Wirkungskontrolle können dazu führen, dass der implementierte Algorithmus optimiert wird.
Kurzfristige Anpassungen:
Gerade in der ersten Zeit nach Einführung einer Data Science Lösung in den produktiven Betrieb gibt es Bedarf nach Optimierung des Algorithmus. In dieser Phase gibt es oft die ersten Ergebnisse der Wirkungskontrolle, die einen Aufschluss über die Effektivität des Algorithmus geben.
Um relativ kurzfristig Änderungen am Code vorzunehmen, zu testen und in Produktion auszurollen, benötigt man kurze Releasezyklen. Längere Releasezyklen wie z.B. ein Release pro Quartal sind hier nicht akzeptabel.
Der Code im Prototyp muss deswegen übersichtlich, gut dokumentiert und einfach und schnell wartbar sein. Das ist aber speziell nach einer prototypischen Entwicklung oft nicht gegeben. Dieser Code enthält meistens Abschnitte, die sehr oft modifiziert wurden oder evtl. gar nicht mehr benötigt werden. Möglicherweise muss also dieser Code «entschlackt» werden. Der Umfang dieser Arbeit kann von Anpassungen einzelner Code-Strecken bis zur kompletten Neu-Implementierung des Codes variieren.
Das hierbei notwendige Code-Reengineering deckt sich mit der Arbeit, die für die oben beschriebene Dokumentation der fachlichen Vorgaben notwendig ist.
Operationalisierung von Data Science Lösungen – Teil 2
Im zweiten Teil dieses Blogs wird näher beschrieben wie der Pilotbetrieb pragmatisch implementiert werden kann und inwiefern er sich vom initialen Prototypen auf der einen Seite und vom späteren regulären Betrieb auf der anderen Seite abgrenzt.
Die Arbeit von Data Scientisten und Analysten ähnelt der Arbeitsweise von Forschern: sie versuchen Algorithmen und damit Lösungen zu finden, die aus den Daten Ihres Unternehmens einen Mehrwert erschaffen können, z.B. durch personalisiertes Marketing. Es ist aber nicht die Aufgabe und in der Regel auch nicht Teil der Jobbeschreibung eines Data Scientisten, solche Lösungen in ein Produkt oder eine operative Lösung zu überführen. Wenn die Stakeholder aber von der Lösung überzeugt sind, gilt es diese möglichst schnell und effizient zu operationalisieren. In vielen Fällen dauert der offizielle Weg, z.B. über ein Projekt in der IT-Abteilung zu lange.
In diesem zweiteiligen Blog wird beschrieben, wie man trotzdem die Lösung möglichst schnell und stabil in den produktiven Betrieb überführen kann. Im ersten Teil des Blogs wird eine typische Ausgangslage vor der Operationalisierung einer Data Science Lösung beschrieben. Es werden ausserdem die sich daraus ergebenden Ziele und Herausforderungen bei der Operationalisierung abgeleitet und der sog. Pilotbetrieb als Zwischenlösung vorgestellt. Im zweiten Teil des Blogs wird näher beschrieben wie dieser Pilotbetrieb pragmatisch implementiert werden kann und inwiefern er sich vom späteren regulären Betrieb unterscheidet.
- Prototyp: der Data Scientist hat einen Algorithmus in Form eines Prototypen entwickelt. Dieser Prototyp besteht vielleicht aus einer Ansammlung von Skripten in R, Spark, SQL o.ä. Diese Skripte sind auf der Workstation des Data Scientisten abgelegt. Um Ergebnisse der Lösung zu erzielen, werden die Skripte manuell angestossen. Eingabedaten und Laufzeitparameter werden vorher mehr oder weniger manuell aufbereitet.