Alle Jahre wieder kommt ein neuer Trend auf den Markt, welcher die Business Intelligence Welt verändern will. Stark polarisierend sind natürlich Aussagen, welche beschreiben, dass eine Methode die seit Jahren bereits erfolgreich eingesetzt wird, in Zukunft nicht mehr funktioniert und entsprechend alle Organisationen sofort zum neuen Trend hin wechseln müssen, um vor dem Aussterben geschützt zu sein. Nun gut, in den letzten 30 Jahren während denen das Thema Data Warehouse intensiv entwickelt wurde, wurde dessen Aussterben schon oft angedroht, wirklich Einzug gehalten hat es bisher noch nicht. Natürlich gab es eine Evolution über die Zeit mit welcher Standards geschaffen wurden, wie z.B. die Layer-Architektur, die Entwicklungs-Patterns und vor allem auch die Modellierungsansätze, welche u.a. durch Kimball und Inmon geprägt waren. In den letzten Jahren gab es hier Erweiterungen durch Themen wie Big Data, Agilität und Internet of Things. Doch auch hier war es schlussendlich mehr eine Evolution im Sinne einer Ergänzung als einer disruptiven Erneuerung.
Ein vergleichbares Trend-Thema ist zurzeit der Modellierungsansatz Data Vault. Auch hier wurde und wird sehr viel geschrieben, kommuniziert und versprochen. Aus diesem Grund und um zu verstehen, ob Data Vault tatsächlich alles verändern wird, haben wir uns mal genauer angesehen, was dahintersteckt.
Herkunft von Data Vault
Interessant bei Data Vault ist sicherlich die Historie. Entwickelt wurde es bereits 1990 durch Dan Linstedt mit einer ersten Veröffentlichung der Ansätze im Jahr 2000. Jedoch erst 10 Jahre später bekamen diese Ansätze von Linstedt, wie man bei Google Trends gut erkennt, immer mehr Beachtung, sicherlich auch unterstützt durch das erste Buch «The new business supermodel».
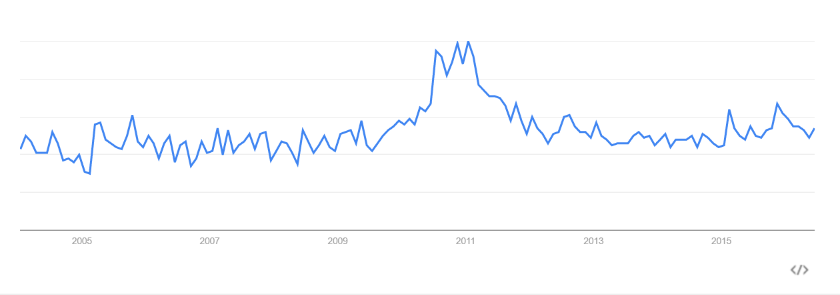
In der Zwischenzeit ist bereits eine überarbeitete und erweiterte zweite Version von Dan Linstedt entwickelt und mit dem Buch «Building a Scalable Data Warehouse with Data Vault 2.0» veröffentlicht worden. Ebenfalls haben sich andere Experten im Bereich Data Vault entwickelt wie z.B. Hans Hultgren, welcher mit dem Buch «Modeling the Agile Data Warehouse with Data Vault» und seiner Trainings-Akademie immer mehr Bekanntheit erlangt.
Grundlagen von Data Vault
Wie die Titel der diversen Bücher beschreiben, steht vor allem die Agilität, Skalierbarkeit sowie die Business Orientierung im Zentrum dieser Modellierungsmethode. Im Vergleich zu den bereits bekannten Modellierungsmethoden wie 3NF oder Dimensional, basiert der Data Vault Ansatz auf dem Prinzip, dass die einzelnen Business Elemente in ihre Bestandteile zerlegt und entsprechend auch physisch in eigenen Tabellen gehalten werden. Hans Hultgren beschreibt dies als «Unified Decomposition».
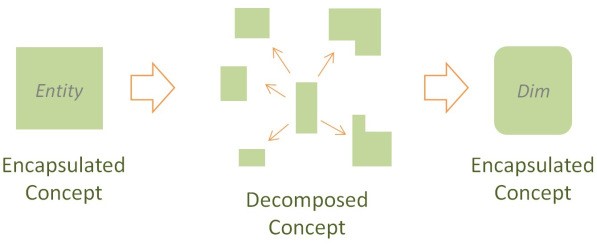
Die Bestandteile werden hierbei wie folgt beschrieben:
- Natürliche Business Identifikatoren/Schlüssel (Primary Key bzw. natürlicher Schlüssel) als Hub (Blau)
- Referenzen (Foreign Keys) als Link (Grün)
- Attribute und Kontexte als Satelliten (Gelb)
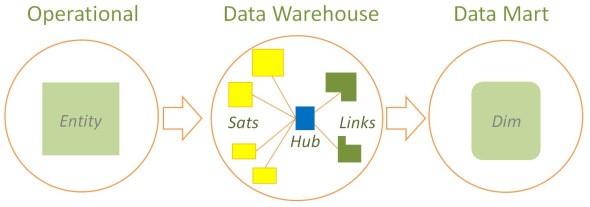
Ein weiteres Konzept, welches Hans Hultgren beschreibt, ist das Data Vault Ensemble. Ein Ensemble bezieht sich dabei auf ein Core Business Concept, wie z.B. der Kunde oder das Produkt und enthält alle dafür notwendigen Bestandteile von Data Vault (Hub, Link und Satelliten). Hierzu ist zu erwähnen, dass die Idee eines Ensembles und deren Bestandteile nicht nur durch Data Vault beschrieben werden. Es gibt weitere Konzepte wie z.B. das Anchor Modelling, welches ebenfalls eine Ausprägung einer Modellierung mit Ensembles ist. Hans Hultgren beschreibt dies unter dem Begriff des Ensemble Modelling, welches viele verschiedene Ausprägungen aufzeigt. Data Vault ist hierbei die bekannteste Ausprägung.
Durch die Abstraktion der einzelnen Bestandteile zu einem Ensemble, können wir uns entsprechend in einer ersten Phase, im Rahmen der Modellierungstätigkeiten, voll auf das Business Konzept konzentrieren. Die Abstraktion der einzelnen Bestandteile als Ensemble ermöglicht eine einfache Kommunikation mit den Business Usern und entsprechend eine vereinfachte Ansicht. Modell-technisch gesehen ist dies sehr nahe am ER-Modell.
Vorteile von Data Vault
Ein Vorteil von Data Vault liegt darin begründet, dass die Verteilung der Bestandteile eines Ensembles in eigene physische Objekte (Hub, Link, Satelliten) es uns erlauben, die Generierung zu automatisieren. Sobald im Modell bzw. den Metadaten beschrieben ist, was der Business Key ist und welche Felder die Relationen beinhaltet, können die einzelnen Tabellen selbstständig erstellt werden. Dies wird dadurch erreicht, dass in den einzelnen Tabellen wirklich nur ein Bestandteil vorhanden ist, wie in der nachfolgenden Grafik von Hans Hultgren anhand der Farben einfach visualisiert wurde. Im Vergleich zu Data Vault erkennt man, dass bei den anderen Modellierungstechniken eine Tabelle jeweils mehrere Bestandteile enthält.

Die Agilität und Skalierbarkeit wird dadurch erreicht, dass jederzeit ein neues Ensemble dem bereits vorhandenen Schema hinzugefügt werden kann, ohne am bestehenden Änderungen vornehmen zu müssen. Ermöglicht wird dies, indem die einzige Verbindung zwischen den Ensembles über die Links hergestellt ist, welche unabhängig in einer eigenen Tabelle gespeichert sind. Durch diese Möglichkeit der stetigen Erweiterungen und der Möglichkeit, über Metadaten die hohe Standardisierung zu automatisieren, sind wir in der Lage eine agile Entwicklung zu erreichen, ohne dass bestehende Artefakte von den Modifikationen direkt betroffen sind.
Herausforderungen
Die hohe Standardisierung über die Verteilung der Bestandteile in eigene physische Komponenten hat jedoch auch den Nachteil, dass die Anzahl Objekte pro Business Konzept, welche in der Datenbank erstellt werden sollen, deutlich höher ist als z.B. in der Dimensionalen Modellierung. Der Aufwand für die Pflege und die Erstellung dieser Objekte ist somit ebenfalls deutlich höher.
Weiter können wir zwar die meisten Herausforderungen, welchen wir bei der Integration in ein Dimensionales Modell gegenüberstehen, bei der Beladung eines Vault Modell zuerst vermeiden, jedoch werden wir auch bei dieser Methode nicht darum herumkommen, die typischen Herausforderungen von BI irgendwann angehen zu müssen. Data Vault selber beschreibt dafür zwei Layer, den Raw Vault sowie den Business Vault, welche zusammen den Kern bilden. Die beiden Layer unterscheiden sich auf Basis der angewendeten Transformationen. So soll der Raw Vault vor allem dafür benutzt werden, die Herkunft der Daten und damit die Auditierbarkeit und Rückverfolgung zu gewährleisten, wobei für den Business Vault bereits die notwendigen Business Regeln angewendet wurden. Aufbauend auf dem Business Vault können dann entsprechende Data Marts erstellt werden, welche im Normallfall wieder ein Dimensionales Modell aufweisen. Das Ziel dabei ist, dass die dimensionalen Modelle lediglich über Views auf Basis des Business Vaults abgebildet werden. Entsprechend agil können diese Modelle erstellt und/oder angepasst werden. Damit verbunden ist eine weitere Herausforderung: Obwohl die Beladung des Data Vault Model Vorteile aufweist, wie z.B. paralleles Laden, haben wir anschliessend aufgrund der vielen benötigen Joins einen höheren Aufwand, die Daten wieder für Auswertungen bereitzustellen.
Fazit und nächste Schritte
Die Herausforderungen zeigen auf, dass auch mit Data Vault bzw. dem Ensemble Modeling die Grundlagen von Data Warehousing nicht komplett revolutioniert werden. Wie bei den meisten Themen der vergangenen Jahre geht es auch hierbei vor allem darum zu verstehen, in welchen Situationen diese Art der Modellierung gegenüber anderen Modellierungstechniken vorzuziehen ist.
Die Tatsache, dass bei IT-Logix verschiedene Berater für die Data Vault Methode zertifiziert sind, zeigt auf, dass wir von den Vorteilen überzeugt sind. Jedoch sind wir auch überzeugt davon, dass nicht bei allen Anforderungen der Einsatz sinnvoll ist und bestimmte Grundlagen vorhanden sein müssen. Bei den folgenden Voraussetzungen kann der Einsatz von Data Vault sinnvoll sein:
- Viele unterschiedliche Quellen
- Hohe Flexibilität bzw. Anpassungsbedarf bei den Quellsystemen
- Schnelle Veränderungen im Business
- Hoher Anspruch an Auditierbarkeit
- Schnelle Releasefähigkeit gewünscht
- Komplexe und verteilte Business Modelle
- Mittleres bis grosses DWH erwartet
Aufgrund der beschriebenen Herausforderungen sehen wir den Einsatz von Automatisierung als wichtige Voraussetzung für die erfolgreiche Operationalisierung eines DWH mit der Data Vault Modellierung. Welche Werkzeuge wir bei IT-Logix dafür nutzen, erfahren Sie im nächsten Blog-Beitrag zu Data Vault.
Referenzen:
Ensemble & Data Vault Modeling von Hans Hultgren
http://de.slideshare.net/HansHultgren/2014-ensemble-modelingpost
Unified Decomposition Blog Beitrag von Hans Hultgren
https://hanshultgren.wordpress.com/2012/10/03/unified-decomposition
Homepage von Dan Linstedt
http://danlinstedt.com/