Im letzten Jahr hat die SAP eine neue cloud-basierte Datawarehousing Lösung lanciert, welche sehr vielversprechend aussieht. Die Lösung nennt sich SAP Datawarehouse Cloud (DWC), und in Zukunft soll die Lösung alle gängigen Use Cases im Umfeld von Data & Analytics abbilden können: Datawarehousing inkl. Historisierung, Modellierung der Daten, Data Governance, KPI Kalkulationen, Data Labs, Data Science Pipelines und zu guter Letzt auch die Visualisierung der Daten. Um die Lösung anzuschauen, stellt die SAP eine 30-Tage-Trial Version zur Verfügung. Unter dieser URL können Sie sich für den Trial registrieren: https://saphanacloudservices.com/data-warehouse-cloud/
In den vergangenen Monaten sind bereits einige Blogs zum Thema Einführung in die SAP DWC verfasst worden. Dieser Blog ist daher keine weitere Einführung in die SAP DWC, sondern hat den Fokus, wie man bereits heute ein umfassendes native Datawarehouse mit der SAP DWC unter Mithilfe von SAP Data Services aufbauen kann.
Falls Sie trotzdem ein paar Zeilen zu den Grundlagen der SAP DWC lesen möchten, sind folgend ein paar interessante Links zum Thema zusammengestellt:
BOAK Präsentation 2019 von Thomas Bitterle (SAP Schweiz):
“What Is SAP Hana Data Warehouse Cloud?” (von Werner Dähn, ex-SAP Software Architect SDI):
https://e3zine.com/sap-hana-data-warehouse-cloud/
“My First story with SAP Datawarehouse Cloud” (von Carlos Pinto, Freelancer aus UK)
https://blogs.sap.com/2020/01/18/my-first-story-with-sap-datawarehouse-cloud/
SAP DWC Roadmap (Stand Oktober 2019):
https://us.v-cdn.net/6031814/uploads/639/1R1NQFQL34EI.pdf
Wenn Sie die obigen Artikel gelesen haben, werden Sie feststellen, dass man nur sehr beschränkte Möglichkeiten hat, Daten in die SAP DWC laden. Es stehen nur Fileupload, OData und SAP Replikation zur Verfügung. Es ist daher nicht möglich 3rd-party Datenquellen einfach anzubinden. Zudem ist es nicht möglich innerhalb der SAP DWC einen ETL Prozess mit verschiedenen Staging Layern aufzubauen und historisierte Datawarehouse Tabellen zu implementieren. Somit ist die Lösung in der aktuellen Version noch recht weit davon entfernt, um eine Datenplattform gemäss IDAREF Blue-print Architektur aufbauen zu können (Link IDAREF: http://www.it-logix.ch/fileadmin/pdf/Fachartikel/20151106_IT-Logix_Data_Governance__Computerworld_.pdf)
Falls Sie jedoch über eine SAP Data Services Lizenz verfügen, kommt man der IDAREF Blue-print Architektur bereits sehr nahe. Mittels SAP Data Services kann man einfach und schnell «any data» in die SAP DWC laden, Historisierung von Daten einfach umsetzen, Profilings von Daten erstellen und auch Datenqualitätsfunktionen wie z.B. Address Cleansing, GeoCoding oder Fuzzy Matchings erstellen.
In den letzten Wochen habe ich daher ein end2end Datawarehouse Szenario in der SAP DWC erstellt, welches in groben Zügen in diesem Blog beschrieben wird:
Szenario:
Die Firma Adventureworks möchte seine Sales Zahlen einfach auswerten können, und historisch alle Veränderungen in den Daten festhalten können. Zudem möchten sie eine Analyse erstellen, welche zeigt in welchen Verkaufsgebieten die höchsten Rabatte im Verhältnis zu den verkaufen Mengen gewährt werden, um die Rabattvergabe optimieren zu können.
Die Rohdaten für diese Analyse sind in einer SQL Server Datenbank abgespeichert und man möchte diese Daten in der SAP DWC auswerten.
Infrastruktur-Architektur:
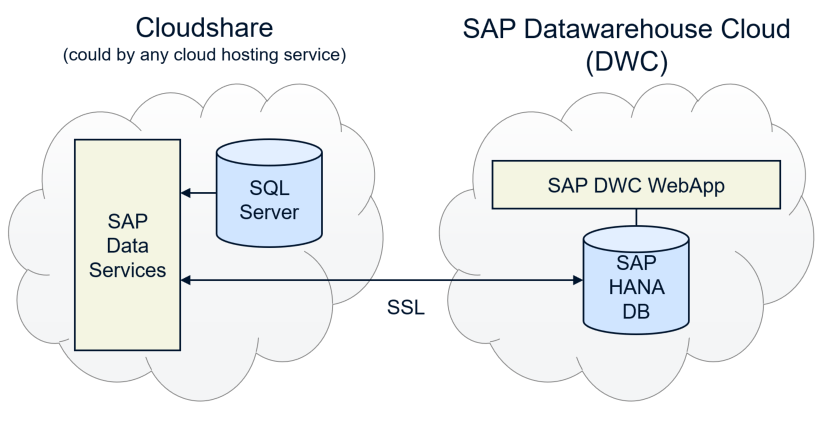
Datenquelle:
Auf dem SQL Server in der Cloudshare ist die Adventureworks Datenbank. Hier dargestellt ist das Datenmodell dieser Datenquelle:
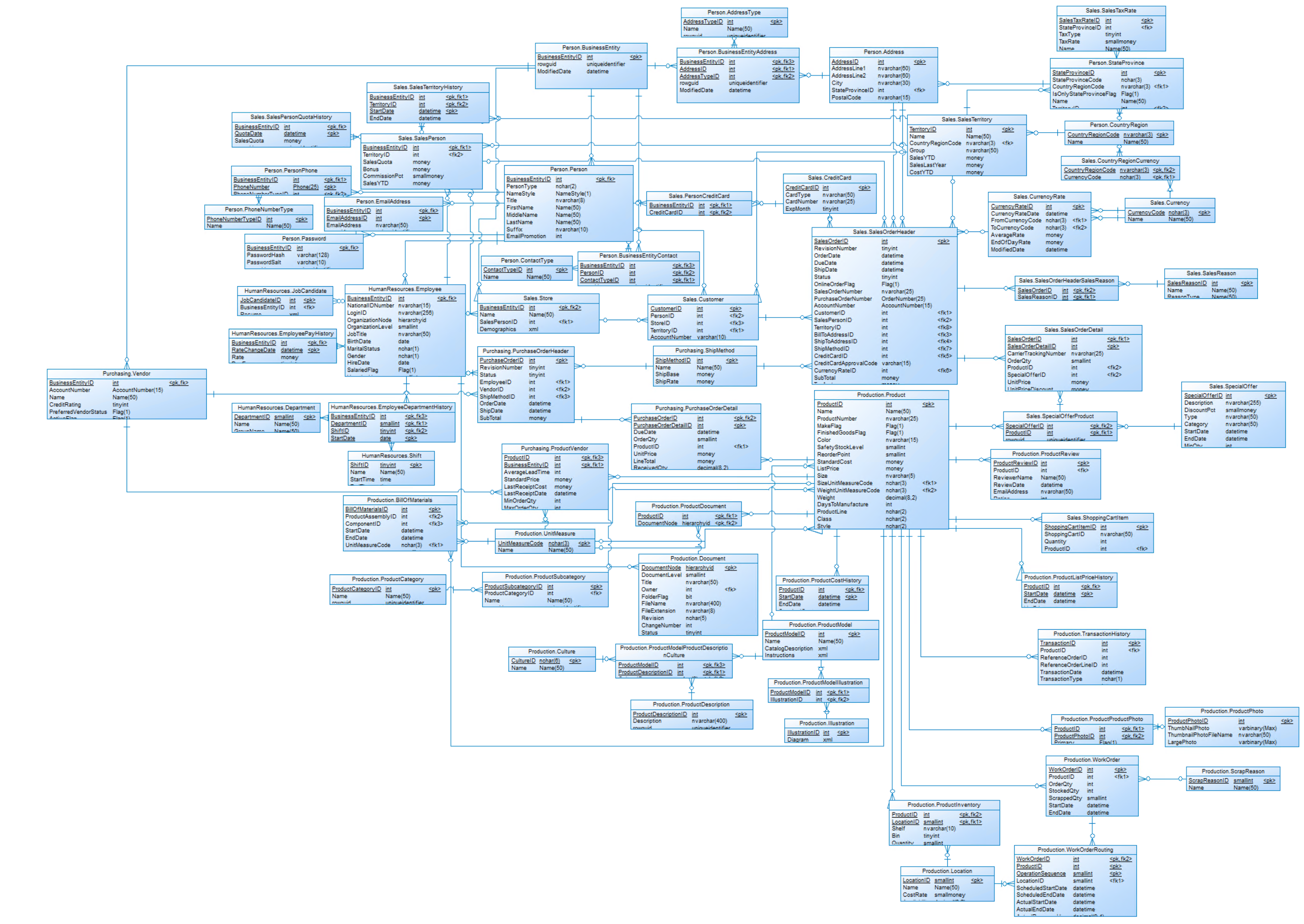
DWH Datenmodell:
Das Zielmodell, um ein einfaches Reporting zu ermöglichen und die historisierten Daten abzuspeichern sieht wie folgt aus:

ETL Layer Architektur:
Um eine nachhaltige Architektur aufzubauen, in welcher auch weitere Datenquellen angebunden werden können, wurde die ITX Standard DWH Layer Architektur implementiert. Für dieses Szenario wurden die rot markierten Komponenten benötigt:
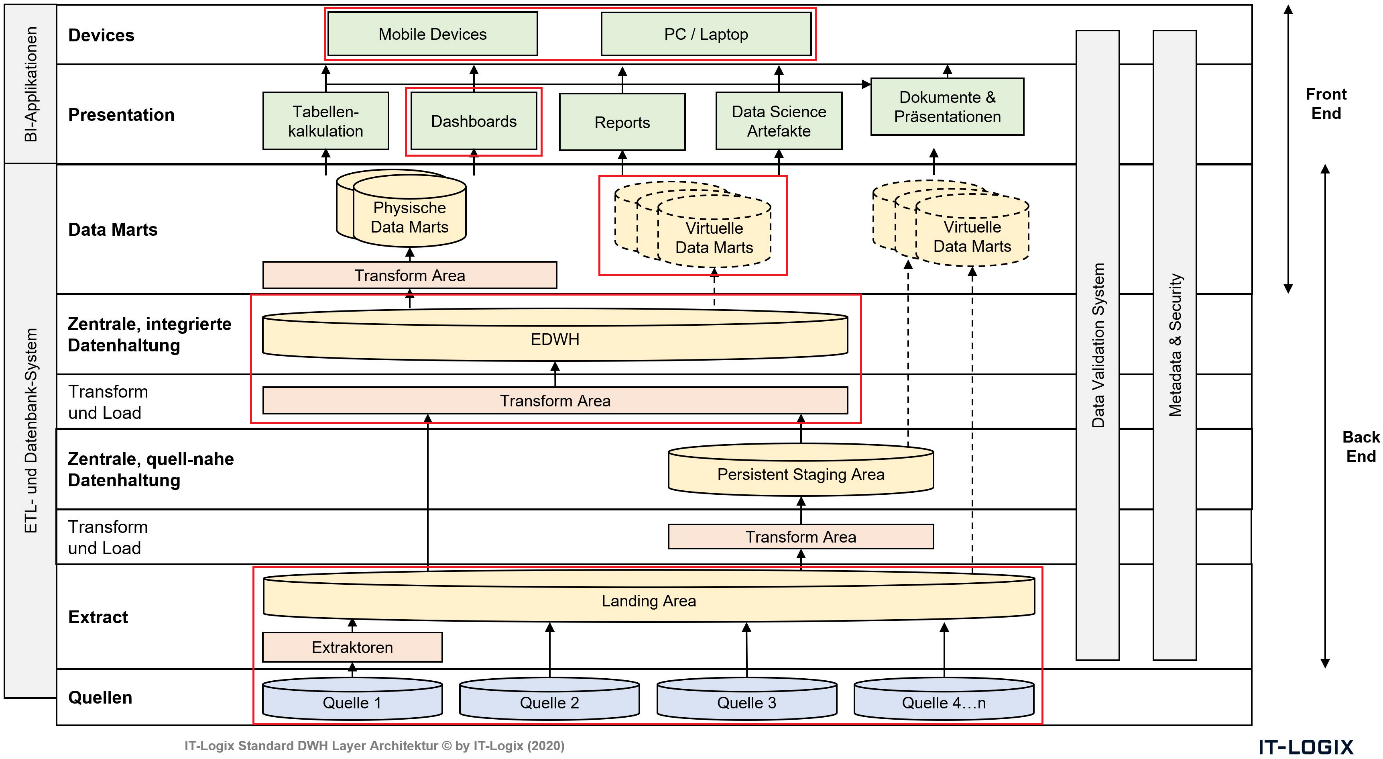
Innerhalb von SAP Data Services sieht die Implementation schlussendlich wie folgt aus:
Load der Adventureworks Datenbank in die SAP DWC:
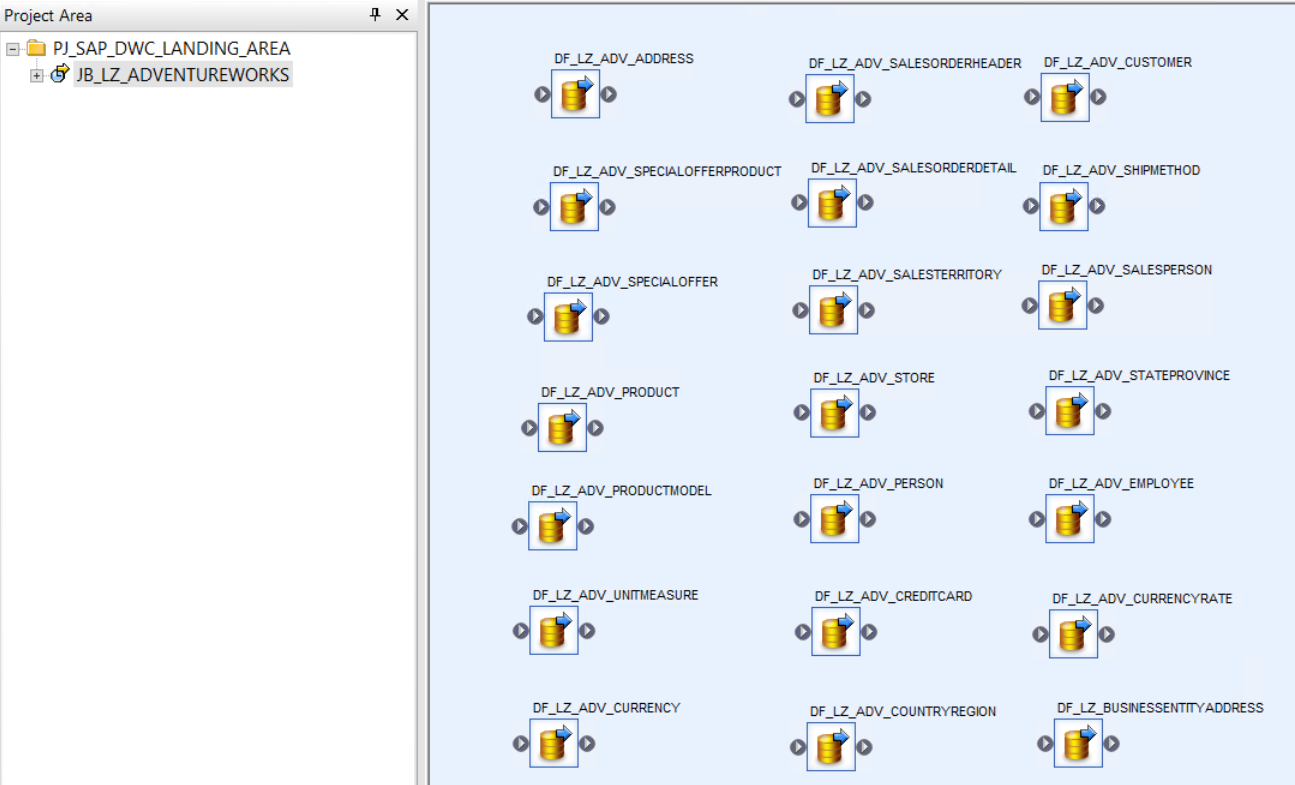
Innerhalb der Datenflüsse, welche die Daten 1:1 in die SAP DWC laden wird eine BATCH_RUN_ID hinzugefügt, damit die Nachvollziehbarkeit sichergestellt werden kann.
Um danach die Daten ins DWH Datenmodell zu laden und zu historisieren werden zwei zusätzliche Schritte benötigt. Zuerst muss die Transformationslogik definiert werden. Diese wurde auf der SAP DWC direkt mittels Datenbank Views implementiert. Dafür wurde das Open Source SQL Tool DBeaver eingesetzt. Als Beispiel sieht die Implementation der Kundendimension folgendermassen aus:
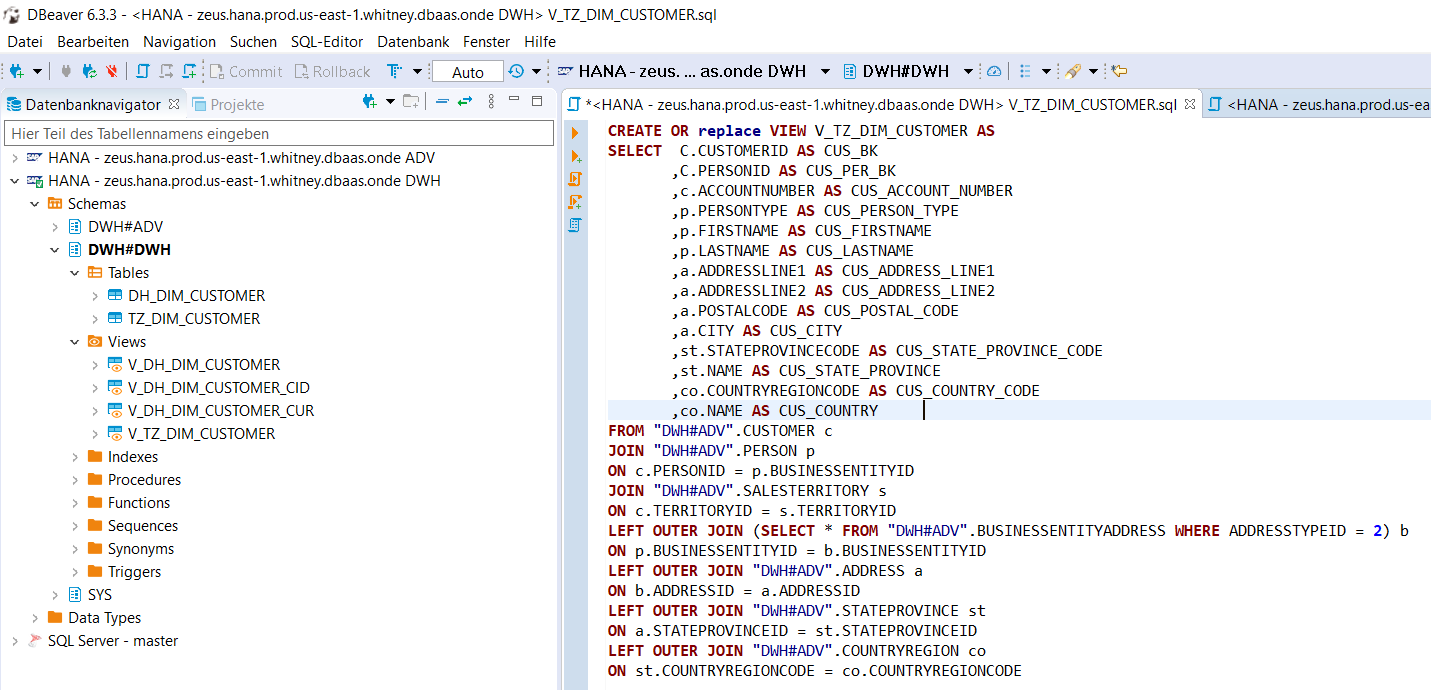
Diese Implementation ist im Moment leider noch etwas unschön, denn die Grundidee ist gewesen, eine solche Transformationslogik mit dem Data Builder in der SAP DWC zu implementieren und diese Views dann wieder in den SAP Data Services ETL Prozess einzubeziehen. Leider funktioniert das heute noch nicht, die mit dem Data Builder erstellten Views (graphical und SQL Views) über ein 3-party Tool wie SAP Data Services zu konsumieren. Das sollte sich gemäss Roadmap aber bald ändern.
Die oben erstellte View wird in eine Transformation Tabelle geladen (aus Gründen der Entkoppelung und der Robustheit des ETL Loads) und danach mit SAP Data Services Mitteln die eigentliche historisierte DWH Tabelle geladen.
Der end2end Workflow und der Datenfluss für die Historisierung in SAP Data Services sieht schlussendlich wie folgt aus (links Ablauflogik, rechts Historisierung):
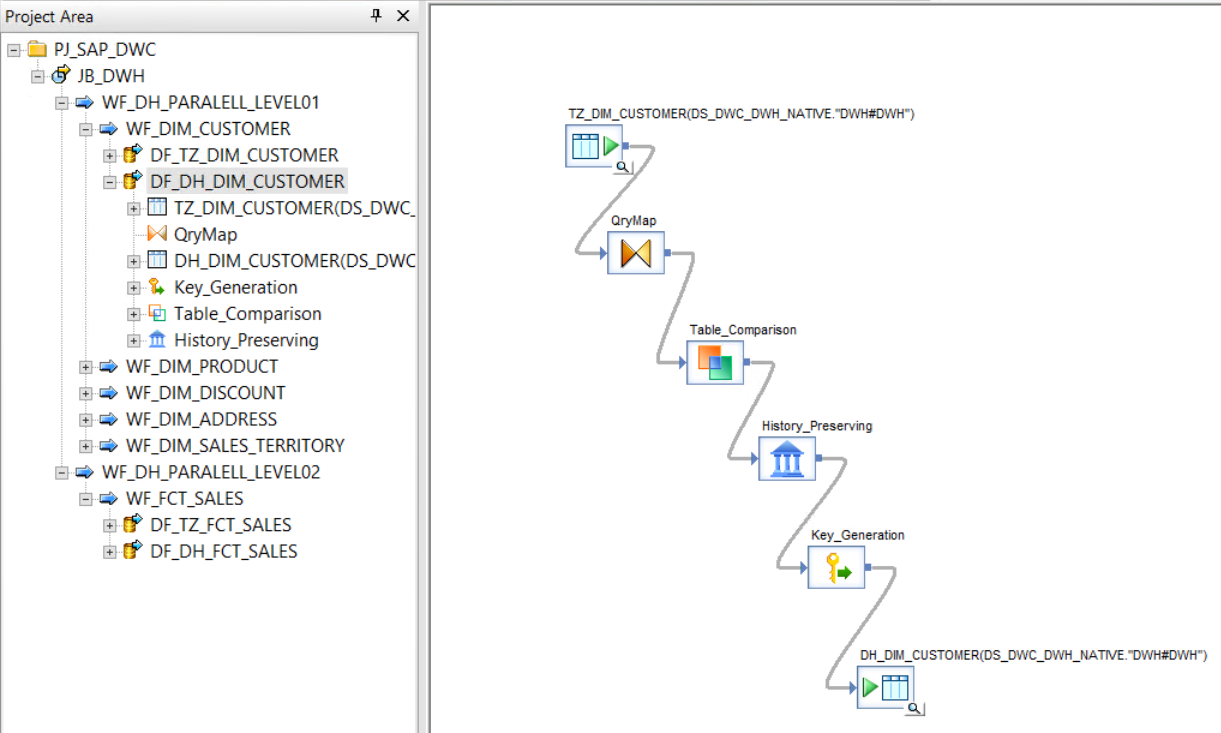
Nachdem die Daten in die SAP DWC geladen und historisiert wurden, kann nun in der SAP DWC das Datenmodell erstellt werden (vgl. Abbildung Zieldatenmodell oben) und die dafür benötigte analytische View. Danach kann die Visualisierung mit dem Story Builder erstellt werden.
Die grafische analytische View sieht in unserem Beispiel so aus:
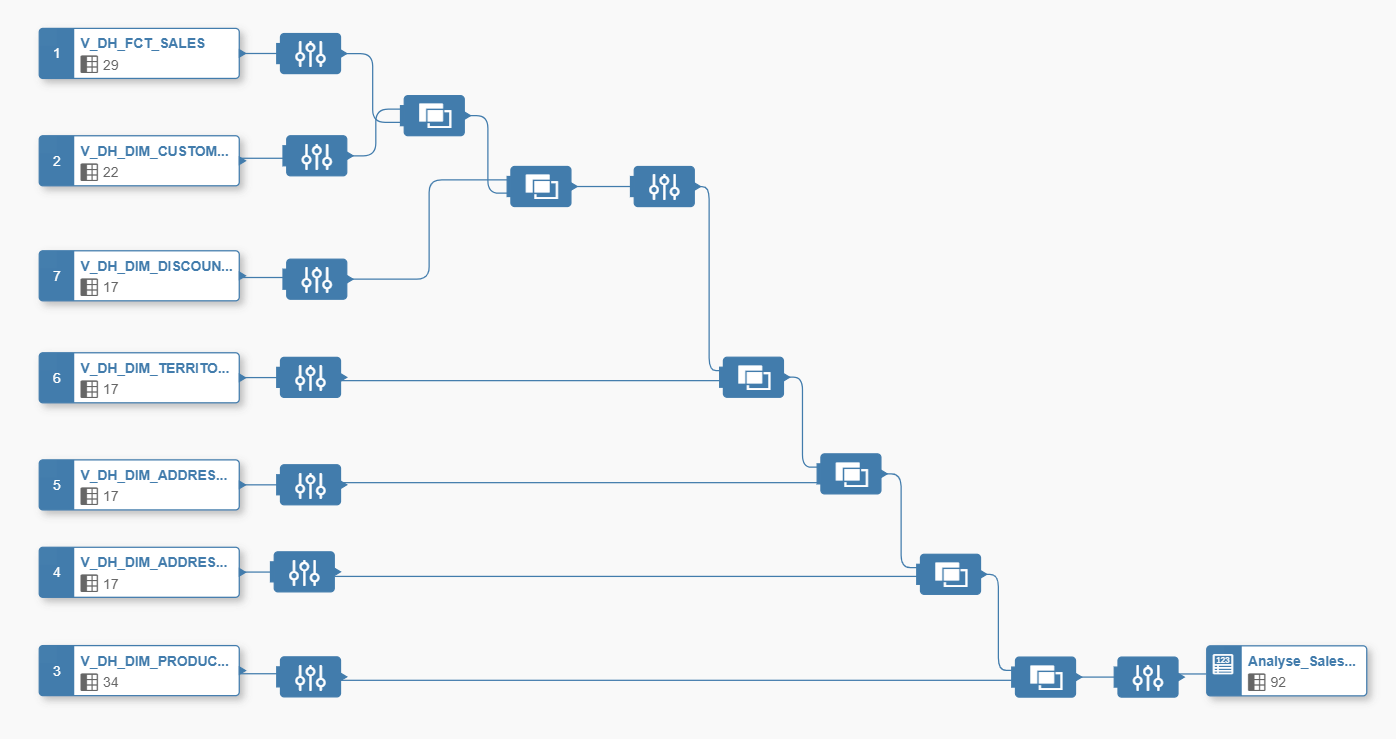
Nachdem die View als analytische View erstellt wurde, kann diese im Story Builder verwendet werden. Wie eingangs beschrieben, kann nun mittels der unten dargestellten Visualisierung analysiert werden, welches Verkaufsgebiet, die höchsten Rabatte im Vergleich zu der verkauften Menge gewährt:
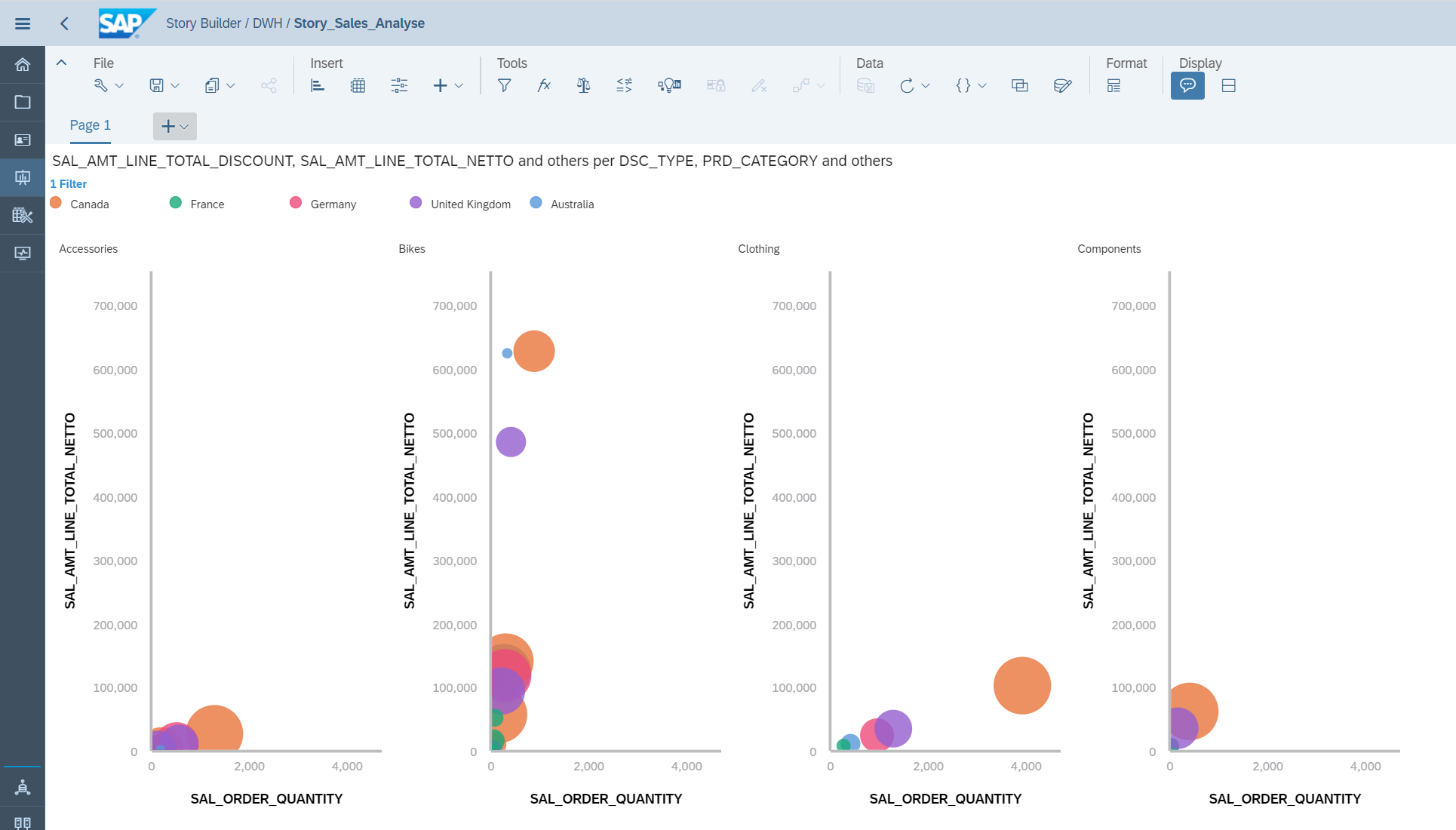
Zusammenfassung:
Wie dieses Beispiel Szenario aufzeigt, ist es bereits heute möglich ein natives Datawarehouse in der SAP DWC unter Mithilfe von SAP Data Services umzusetzen. Also sollten Sie in Betracht ziehen, in nächster Zeit Ihre bestehende Datawarehouse Umgebung in Richtung SAP DWC verschieben zu wollen, dann ist das grundsätzlich bereits heute möglich, obwohl in der SAP DWC heute die nötigen Features, um ein natives Datawarehouse aufzubauen noch nicht vollständig vorhanden sind.
Selbstverständlich können Sie den Aufbau eines nativen Datawarehouses in der SAP DWC nicht nur mittels SAP Data Services umsetzen. Dafür können Sie jedes verfügbare 3rd-party ETL Tool verwenden, wie z.B. Wherescape, SnapLogic oder Informatica. Da der Aufbau und die Konzeption eines nativen Datawarehouses grundsätzlich immer sehr ähnlich aussieht, können wir Sie als IT-Logix sehr umfassend und herstellerneutral in allen Belangen rund um natives Datawarehousing beraten.
Falls dieser Blog Ihr Interesse an der SAP DWC und an nativen Datawarehousing geweckt hat, würde ich mich sehr über eine Kontaktaufnahme freuen oder Sie schreiben ganz einfach unten in der Kommentarbox Ihre Meinung zu diesem Blog.
Im letzten Jahr hat die SAP eine neue cloud-basierte Datawarehousing Lösung lanciert, welche sehr vielversprechend aussieht. Die Lösung nennt sich SAP Datawarehouse Cloud (DWC), und in Zukunft soll die Lösung alle gängigen Use Cases im Umfeld von Data & Analytics abbilden können: Datawarehousing inkl. Historisierung, Modellierung der Daten, Data Governance, KPI Kalkulationen, Data Labs, Data Science Pipelines und zu guter Letzt auch die Visualisierung der Daten. Um die Lösung anzuschauen, stellt die SAP eine 30-Tage-Trial Version zur Verfügung. Unter dieser URL können Sie sich für den Trial registrieren: https://saphanacloudservices.com/data-warehouse-cloud/
In den vergangenen Monaten sind bereits einige Blogs zum Thema Einführung in die SAP DWC verfasst worden. Dieser Blog ist daher keine weitere Einführung in die SAP DWC, sondern hat den Fokus, wie man bereits heute ein umfassendes native Datawarehouse mit der SAP DWC unter Mithilfe von SAP Data Services aufbauen kann.
Falls Sie trotzdem ein paar Zeilen zu den Grundlagen der SAP DWC lesen möchten, sind folgend ein paar interessante Links zum Thema zusammengestellt:
BOAK Präsentation 2019 von Thomas Bitterle (SAP Schweiz):
“What Is SAP Hana Data Warehouse Cloud?” (von Werner Dähn, ex-SAP Software Architect SDI):
https://e3zine.com/sap-hana-data-warehouse-cloud/
“My First story with SAP Datawarehouse Cloud” (von Carlos Pinto, Freelancer aus UK)
https://blogs.sap.com/2020/01/18/my-first-story-with-sap-datawarehouse-cloud/
SAP DWC Roadmap (Stand Oktober 2019):
https://us.v-cdn.net/6031814/uploads/639/1R1NQFQL34EI.pdf
Wenn Sie die obigen Artikel gelesen haben, werden Sie feststellen, dass man nur sehr beschränkte Möglichkeiten hat, Daten in die SAP DWC laden. Es stehen nur Fileupload, OData und SAP Replikation zur Verfügung. Es ist daher nicht möglich 3rd-party Datenquellen einfach anzubinden. Zudem ist es nicht möglich innerhalb der SAP DWC einen ETL Prozess mit verschiedenen Staging Layern aufzubauen und historisierte Datawarehouse Tabellen zu implementieren. Somit ist die Lösung in der aktuellen Version noch recht weit davon entfernt, um eine Datenplattform gemäss IDAREF Blue-print Architektur aufbauen zu können (Link IDAREF: http://www.it-logix.ch/fileadmin/pdf/Fachartikel/20151106_IT-Logix_Data_Governance__Computerworld_.pdf)
Falls Sie jedoch über eine SAP Data Services Lizenz verfügen, kommt man der IDAREF Blue-print Architektur bereits sehr nahe. Mittels SAP Data Services kann man einfach und schnell «any data» in die SAP DWC laden, Historisierung von Daten einfach umsetzen, Profilings von Daten erstellen und auch Datenqualitätsfunktionen wie z.B. Address Cleansing, GeoCoding oder Fuzzy Matchings erstellen.
In den letzten Wochen habe ich daher ein end2end Datawarehouse Szenario in der SAP DWC erstellt, welches in groben Zügen in diesem Blog beschrieben wird:
Szenario:
Die Firma Adventureworks möchte seine Sales Zahlen einfach auswerten können, und historisch alle Veränderungen in den Daten festhalten können. Zudem möchten sie eine Analyse erstellen, welche zeigt in welchen Verkaufsgebieten die höchsten Rabatte im Verhältnis zu den verkaufen Mengen gewährt werden, um die Rabattvergabe optimieren zu können.
Die Rohdaten für diese Analyse sind in einer SQL Server Datenbank abgespeichert und man möchte diese Daten in der SAP DWC auswerten.
Infrastruktur-Architektur:
Datenquelle:
Auf dem SQL Server in der Cloudshare ist die Adventureworks Datenbank. Hier dargestellt ist das Datenmodell dieser Datenquelle:
DWH Datenmodell:
Das Zielmodell, um ein einfaches Reporting zu ermöglichen und die historisierten Daten abzuspeichern sieht wie folgt aus:
ETL Layer Architektur:
Um eine nachhaltige Architektur aufzubauen, in welcher auch weitere Datenquellen angebunden werden können, wurde die ITX Standard DWH Layer Architektur implementiert. Für dieses Szenario wurden die rot markierten Komponenten benötigt:
Innerhalb von SAP Data Services sieht die Implementation schlussendlich wie folgt aus:
Load der Adventureworks Datenbank in die SAP DWC:
Innerhalb der Datenflüsse, welche die Daten 1:1 in die SAP DWC laden wird eine BATCH_RUN_ID hinzugefügt, damit die Nachvollziehbarkeit sichergestellt werden kann.
Um danach die Daten ins DWH Datenmodell zu laden und zu historisieren werden zwei zusätzliche Schritte benötigt. Zuerst muss die Transformationslogik definiert werden. Diese wurde auf der SAP DWC direkt mittels Datenbank Views implementiert. Dafür wurde das Open Source SQL Tool DBeaver eingesetzt. Als Beispiel sieht die Implementation der Kundendimension folgendermassen aus:
Diese Implementation ist im Moment leider noch etwas unschön, denn die Grundidee ist gewesen, eine solche Transformationslogik mit dem Data Builder in der SAP DWC zu implementieren und diese Views dann wieder in den SAP Data Services ETL Prozess einzubeziehen. Leider funktioniert das heute noch nicht, die mit dem Data Builder erstellten Views (graphical und SQL Views) über ein 3-party Tool wie SAP Data Services zu konsumieren. Das sollte sich gemäss Roadmap aber bald ändern.
Die oben erstellte View wird in eine Transformation Tabelle geladen (aus Gründen der Entkoppelung und der Robustheit des ETL Loads) und danach mit SAP Data Services Mitteln die eigentliche historisierte DWH Tabelle geladen.
Der end2end Workflow und der Datenfluss für die Historisierung in SAP Data Services sieht schlussendlich wie folgt aus (links Ablauflogik, rechts Historisierung):
Nachdem die Daten in die SAP DWC geladen und historisiert wurden, kann nun in der SAP DWC das Datenmodell erstellt werden (vgl. Abbildung Zieldatenmodell oben) und die dafür benötigte analytische View. Danach kann die Visualisierung mit dem Story Builder erstellt werden.
Die grafische analytische View sieht in unserem Beispiel so aus:
Nachdem die View als analytische View erstellt wurde, kann diese im Story Builder verwendet werden. Wie eingangs beschrieben, kann nun mittels der unten dargestellten Visualisierung analysiert werden, welches Verkaufsgebiet, die höchsten Rabatte im Vergleich zu der verkauften Menge gewährt:
Zusammenfassung:
Wie dieses Beispiel Szenario aufzeigt, ist es bereits heute möglich ein natives Datawarehouse in der SAP DWC unter Mithilfe von SAP Data Services umzusetzen. Also sollten Sie in Betracht ziehen, in nächster Zeit Ihre bestehende Datawarehouse Umgebung in Richtung SAP DWC verschieben zu wollen, dann ist das grundsätzlich bereits heute möglich, obwohl in der SAP DWC heute die nötigen Features, um ein natives Datawarehouse aufzubauen noch nicht vollständig vorhanden sind.
Selbstverständlich können Sie den Aufbau eines nativen Datawarehouses in der SAP DWC nicht nur mittels SAP Data Services umsetzen. Dafür können Sie jedes verfügbare 3rd-party ETL Tool verwenden, wie z.B. Wherescape, SnapLogic oder Informatica. Da der Aufbau und die Konzeption eines nativen Datawarehouses grundsätzlich immer sehr ähnlich aussieht, können wir Sie als IT-Logix sehr umfassend und herstellerneutral in allen Belangen rund um natives Datawarehousing beraten.
Falls dieser Blog Ihr Interesse an der SAP DWC und an nativen Datawarehousing geweckt hat, würde ich mich sehr über eine Kontaktaufnahme freuen oder Sie schreiben ganz einfach unten in der Kommentarbox Ihre Meinung zu diesem Blog.