Beim Erstellen eines neuen Data Warehouse oder eines Data Lake stellt sich unter anderem die Frage, ob Sie eine Persistent Staging Area (PSA) generieren möchten.
In diesem Blog zeigen wir Ihnen, was eine PSA ist, welche Vorteile sie hat, welche Entwurfsmuster diese erstellt und abschliessend, wie Sie diese Muster mit einem Data Warehouse Automation Toolset wie dem von WhereScape implementieren können.
Vorteile einer Persistent Staging Area
Beginnen wir damit, wie eine PSA aussehen könnte:
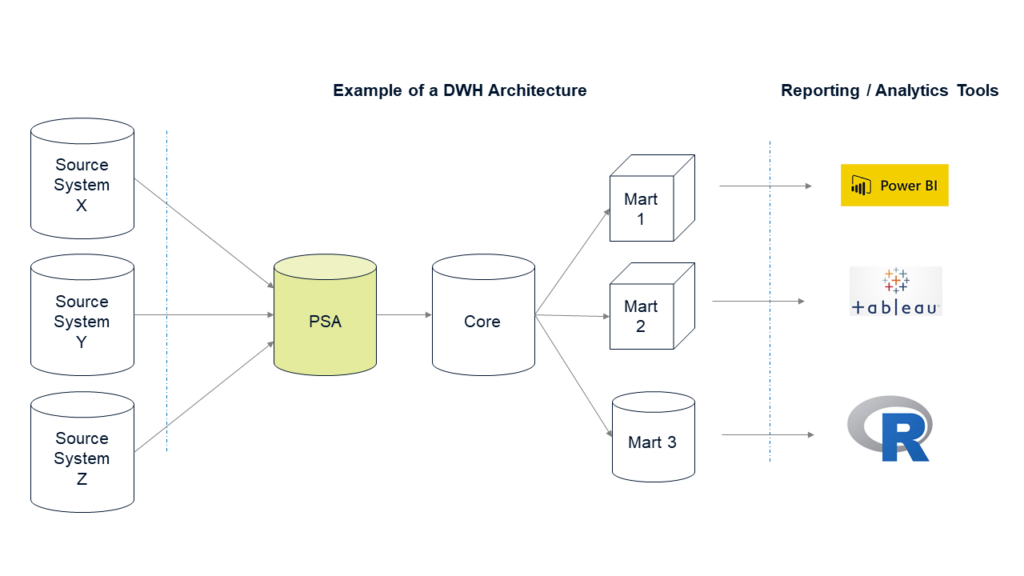
- Eine Datenbank oder ein Schema, in dem alle benötigten Tabellen von einem oder mehreren Quellsystemen eins zu eins übertragen werden (keine Transformationen zulässig, ausser dem Hinzufügen einiger Spalten wie eines Zeitstempels oder eines Batch Key).
- In der PSA haben Sie einen historischen Überblick über Datenänderungen im Quellsystem. Dies bedeutet, dass Sie sogenannte „as of “ -Abfragen durchführen können, die die Daten so zurückgeben, wie sie zu einem bestimmten Zeitpunkt ausgesehen haben (natürlich abhängig davon, wie häufig Sie neue / geänderte Daten in die PSA laden).
- Diese wichtige Funktion zur Unterstützung von „as of“-Abfragen setzt voraus, dass Sie die im Quellsystem gelöschten Zeilen verfolgen und in der PSA markieren müssen. Andernfalls führen diese „as of“-Abfragen nicht zu genau den gleichen Ergebnissen. Dies ist eine knifflige Anforderung, auf die wir weiter unten in diesem Artikel näher eingehen werden.
Mit einer solchen PSA erhalten Sie alle historischen Datenänderungen, seit Sie mit dem Laden der Daten begonnen haben. Dies hat folgende Vorteile:
- Das Laden neuer Daten in die PSA kann weitgehend automatisiert werden, wie wir in diesem Artikel zeigen werden. Daher ist das Laden (und Historisieren) von Daten nicht sehr aufwändig. Sie können sich Zeit nehmen, um Ihr (Core-) Data Warehouse ordnungsgemäss zu modellieren und neue Daten aus der PSA zu laden.
- Historische Daten sind in der PSA verfügbar, die möglicherweise im Quellsystem selbst nicht mehr verfügbar sind.
- „Responding to change over following a plan” (Zitat agilen Manifesto) : Beispielsweise müssen Sie eines der Module im Data Warehouse aufgrund geänderter Geschäftsanforderungen massiv erweitern. Wenn Sie die erweiterten Anforderungen hinzufügen, können Sie das angepasste Modell zunächst mit den bereits in der PSA verfügbaren Verlaufsdaten laden.
- Verkürzung der Entwicklungszeit und des initialen Ladens, ohne das Quellsystem mit hohen Performanceansprüchen zu belasten.
Basic Design Pattern
Für die Implementierung einer PSA haben wir die entsprechenden Design Pattern in grundlegende (basic) und erweiterte (advanced) unterteilt. In der folgenden Abbildung sehen Sie eine grundlegende Implementation einer PSA, bei der die folgenden Annahmen gelten:
- Wir laden die Daten vollständig, nicht im Delta.
- Für jede Tabelle führen wir die technische Historisierung in der PSA aus (die technische Historisierung kann auf verschiedene Arten erfolgen, z. B. nur durch Insert Only, Snapshots oder SCD2 ( Slowly Changing Dimensions type 2). In diesem Blog-Beitrag werden wir nicht auf die Details dieser Historisierungstypen eingehen.)
- Das Quellsystem informiert uns, falls Daten physisch gelöscht wurden (z. B. mit einem Löschflag in der Quelltabelle selbst).
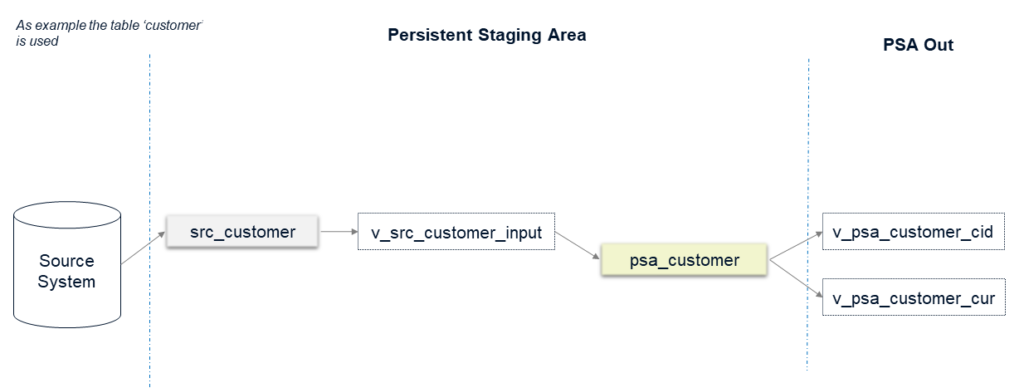
In diesem Beispiel haben wir die Tabelle „Kunde“ (bzw. Customer) aus dem Quellsystem X genommen.
Lassen Sie uns die verschiedenen Objekte erklären, die Sie im Diagramm sehen:
- src_customer: Daten aus dem Quellsystem werden eins zu eins übertragen. Es sind keine Geschäftstransformationen zulässig. Die Tabelle wird immer geleert, bevor ein neuer Load gestartet wird.
- v_src_customer_input: Eine View, die als Schnittstelle zum Laden der Daten in die (persistente) PSA-Tabelle verwendet wird. Normalerweise wählt diese View nur die Daten aus, ohne dass eine Logik hinzugefügt wird. Bei einigen Quellsystemen müssen jedoch grundlegende Datenqualitätsprüfungen hinzugefügt werden, z. B. die Überprüfung doppelter Primärschlüssel.
- psa_customer: Diese Tabelle enthält die historisierten Daten der Kundentabelle. In dieser Tabelle finden Sie alle Änderungen für jeden vom ETL / ELT-Prozess geladenen Datensatz, z. B. unter Verwendung eines SCD2-Musters.
- v_psa_customer_cid: Diese View wird als Schnittstelle für nachfolgende Ebenen verwendet, z. B. das Core Warehouse. CID steht für “current records including deletes”, also alle aktuell gültigen Datensätze (einschliesslich solcher, bei denen das Löschflag auf „Ja“ gesetzt ist).
- v_psa_customer_cur: wie oben, jedoch ohne gelöschte Datensätze.
Wie in den obigen Annahmen beschrieben, gehen wir davon aus, dass die Löscherkennung vom Quellsystem selbst übernommen wird. Und diese Daten werden immer wieder vollständig geladen. Bei einigen Projekten funktioniert dies einwandfrei. In vielen Situationen müssen Sie aber grosse Tabellen mit einem Deltaprozess laden. Darüber hinaus unterstützen viele Quellsysteme die Löscherkennung leider nicht. In solchen Fällen müssen wir die PSA um eine Logik erweitern, wie im nächsten Absatz beschrieben.
Advanced Design Pattern
Das Advanced Design Pattern erweitert das Basic Design Pattern um mehrere Datenbankobjekte:
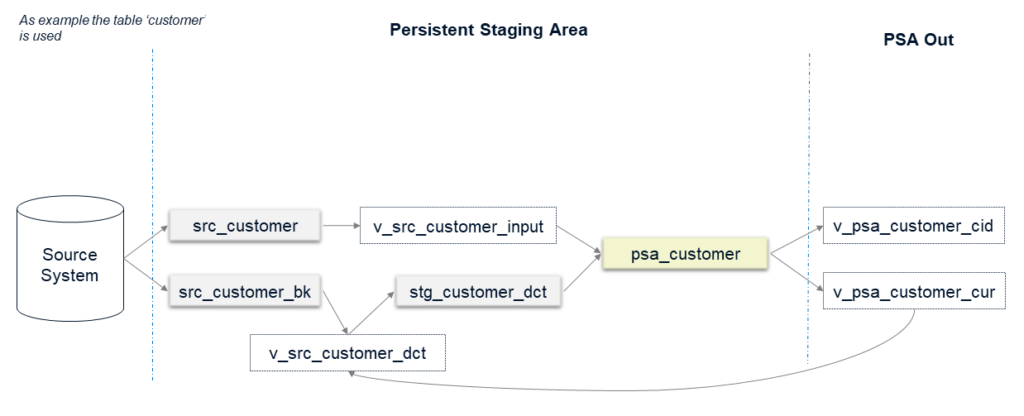
Schauen wir uns diese Objekte genauer an:
- v_src_customer_dct: Diese View ist zuständig für die Löscherkennung (dct). Für Tabellen, die im Vollmodus geladen werden, führt die View Folgendes aus (Die Logik für inkrementell geladene Tabellen wird weiter unten erläutert):
- Überprüfen Sie alle Zeilen, die aus der Ansicht v_psa_customer_cur stammen, und vergleichen Sie diese mit allen Zeilen, die in die Tabelle src_customer geladen werden. Für Datensätze, die nur noch in der PSA-View, aber nicht mehr in der src-Tabelle vorhanden sind, können wir davon ausgehen, dass sie physisch aus dem Quellsystem gelöscht wurden.
- Diese View gibt nur die fehlenden Zeilen zurück und markiert das Feld „deleted_in_source“ mit „Yes“.
- stg_customer_dct: Die Zeilen, die in der View v_src_customer_dct als gelöscht markiert sind, werden vorübergehend in dieser Staging-Tabelle gespeichert und anschliessend in die Tabelle psa_customer geladen (wobei zu berücksichtigen ist, dass das Flag „deleted_in_source“ auf „Yes“ gesetzt ist).
- src_customer_bk: Diese Tabelle wird nur für Tabellen erstellt, die im Delta-Modus geladen werden. Das einzige Ziel besteht darin, die Option zur Implementierung der Löscherkennung zu aktivieren:
- Bei inkrementell geladenen Tabellen können Sie gelöschte Datensätze in der Quelle nicht wie oben erläutert erkennen.
- Deswegen erstellen wir diese bk-Tabelle, die nur aus den Business-Key-Spalten der angegebenen Quelltabelle besteht (da die PSA sehr quellsystemgesteuert ist, ist der Business Key hier häufig derselbe wie der Primärschlüssel der Quellsystemtabelle, welcher die Quellzeile eindeutig identifiziert).
- Nach dem Laden aller Daten verwendet die Löscherkennungsview (v_src_customer_dct) die bk-Tabelle als Input, um zu überprüfen, ob Zeilen im Quellsystem gelöscht wurden.
- Diese bk-Tabellen werden nur im Vollmodus geladen. Das Laden von nur einem oder wenigen Attributen ist in der Regel schneller als das Gleiche für die gesamte Tabelle. Eine saubere Indizierung kann zudem den Löscherkennungsprozess beschleunigen.
- Wenn das vollständige Laden der bk-Tabellen immer noch zu lange dauert, führen Sie diesen Load möglicherweise nur einmal pro Woche oder noch seltener aus.
Minimierung der PSA-Investition durch Data Warehouse Automation
Angesichts der obigen Erläuterungen stellen Sie fest, dass eine solche PSA eine Menge Datenbankobjekte und -logik für jede einzelne Quellentabelle benötigt. Das manuelle Erstellen führt zu einer hohen Investition mit viel sich wiederholender Arbeit. Aus langfristiger und architektonischer Sicht ist der Aufbau einer PSA jedoch eine sehr gute Investition, wie in der Einleitung dieses Artikels bereits erläutert. Auf der anderen Seite kann es schwierig sein, es gegenüber Stakeholdern zu verargumentieren, da Ihre Investition in der Startphase Ihres Projekts höher ist, ohne einen direkt sichtbaren Geschäftsnutzen zu haben.
Diese Herausforderung kann mithilfe von DWH Automation angegangen werden. Unser Ziel war es, mit minimalem manuellem Aufwand eine PSA zu generieren, die Löscherkennung, Historisierung und Delta-Handling umfasst. Wir haben WhereScape als Tool-Suite dafür ausgewählt und eine solche Lösung entwickelt. In WhereScape finden Sie zwei Anwendungen, mit denen zusammen Sie die PSA generieren können: WhereScape 3D und WhereScape RED.
WhereScape RED ist die eigentliche Entwicklungsumgebung. Sie definieren dort die Metadaten für jedes benötigte Objekt (wie die oben gezeigten Tabellen und Views) und RED generiert die DDL- und SQL-Anweisungen für Sie und stellt sie in der Zieldatenbank bereit. Auch wenn dies den Prozess bereits enorm beschleunigt, müssen Sie jedes Objekt manuell hinzufügen.
In WhereScape 3D beginnen Sie mit einem Modell der Tabellen Ihres Quellsystems. Anschliessend definieren Sie Model conversion rules. In diesen Regeln können Sie definieren, was mit jeder Quelltabelle unter Verwendung einer Vielzahl von Regeln und Funktionen geschehen soll, z.B. „Entität kopieren“, um die erforderlichen Objekte für jede Quelltabelle abzuleiten. Dadurch können alle benötigten Datenbankobjekte automatisch generiert werden.
Danach können Sie diese Objekte nach RED exportieren und in Ihrer Zieldatenbank bereitstellen. Während RED die Codegenerierung automatisiert, „automatisiert 3D die Automatisierung“, indem RED mit den erforderlichen Metadaten versorgt wird. Hier wird die wahre Kraft der Data Warehouse Automation sichtbar. Es geht aber nicht nur um die Verkürzung der Entwicklungszeit. Die folgenden Aspekte sind ebenfalls sehr wichtige Verkaufsargumente für die Verwendung eines Data Warehouse Automation Ansatzes:
- Qualität und Konsistenz: Da alles mit einer bestimmten Anzahl von Design Pattern generiert wird, treten keine Probleme auf, die durch manuell geschriebenen Code verursacht werden.
- Transparenz und Wartung: Als direkte Folge des vorherigen Punkts ist die Lösung transparent und einfacher zu warten.
- Datenherkunft: Bei Verwendung eines metadatengesteuerten Ansatzes verfügen Sie im gesamten Data Warehouse immer über eine vollständige Datenherkunft aus dem Quellsystem.
- Dokumentation: Mit den Metadaten können Sie automatisch technische Dokumentationen und Benutzerdokumentationen für das Data Warehouse erstellen.
Erkenntnisse & Herausforderungen
WhereScape 3D bietet Ihnen alle Tools zum Definieren aller Ebenen eines Data Warehouse. Sie erhalten jedoch keinen vollständigen Satz gebrauchsfertiger Model Conversion Rules, die dies für Sie erledigen (zumindest nicht, für die in diesem Artikel beschriebenen PSA-Anforderungen). Wir mussten diesen Teil selbst implementieren.
Für die Generierung der Basisversion der PSA war das Einrichten des Generierungsprozesses recht einfach. Als wir den Schritt zur fortgeschrittenen PSA machten, hatten wir einige Herausforderungen, die unkonventionelle Überlegungen erforderten. Diese bezogen sich auf Themen wie
- Unterschiedliche ETL Logik für Delta Loads und Full Loads
- Die PSA-Tabelle ruft Daten aus zwei verschiedenen Quellen ab (Löscherkennung und Delta-Daten).
- Die Löscherkennungsansicht hat auf dem Delta Muster eine andere Logik als auf dem Full Load Muster.
- Einige technische Herausforderungen, z. B. Datentypzuordnungen
3D benötigt einen gewissen Startaufwand, um das Werkzeug initial zu erlernen. Wir empfehlen daher dringend eine Schulung zu besuchen! Sobald Sie aber diese erste Hürde überwunden haben, können Sie eine sehr leistungsfähige und flexible Data Warehouse Automation Umgebung einrichten. Für die Erzeugung der PSA-Schicht haben wir festgestellt, dass das Erzeugen von Objekten mittels 3D der schnellste Weg ist. Die Verwendung der Data Warehouse Automation für das zentrale Data Warehouse wird unsere nächste Herausforderung sein.
Auch die Tatsache, dass WhereScape plattformunabhängig ist, macht die Investition sehr wertvoll. Sie können beispielsweise von Oracle zu Azure SQL migrieren, indem Sie einfach eine andere Zielplattform auswählen. Die erforderliche ETL- und Datenbanklogik wird dann in Azure native SQL-Code generiert.
Vielen Dank fürs Lesen dieses Artikels. Wir hoffen, dass es informativ war. Bei vielen Themen haben wir absichtlich nur and der Oberfläche gekratzt und sind nicht auf zu viele Details eingegangen. Sonst würde der Artikel noch viel länger sein, als er es schon ist :-).
Bitte hinterlassen Sie unten Ihre Kommentare / Fragen, wir würden uns freuen, von Ihnen zu hören!