Im ersten Teil dieses Artikels zur „BI-Produktionslinie“ habe ich aufgezeigt, dass der Aufbau mehrschichtiger Business Intelligence (BI)-Systeme technische und organisatorische Herausforderungen mit sich bringt. Während BI-Systeme normalerweise mittels abstrakter Architekturdiagramme illustriert werden, nutze ich die Analogie von Produktionslinien in einer Datenfabrik, um die verschiedenen Komponenten in einem BI-System mit ihren zugehörigen Aufgaben zu illustrieren. Im zweiten Teil dieses Artikels werde ich nun darauf eingehen, wie man das Bild der Produktionslinie nutzen kann, um die Entwicklungsarbeiten in Makro- und Mikroinkremente zu unterteilen. Zudem werde ich darauf eingehen, was wir uns für eine BI-Produktionslinie von einer „richtigen“ Produktionslinie abschauen können, z.B. hinsichtlich Qualitätssicherung entlang der Produktionslinie oder wie man den Entwicklungsfluss in einem grossen Team optimieren kann.
Makro- und Mikro-Inkremente
Was ist ein Inkrement?
Im Kontext der agilen BI-Entwicklung ist der Begriff «Inkrement» ein Schlüsselbegriff. Ein Inkrement bedeutet zunächst einmal ein Zwischenergebnis einer iterativen Entwicklung. Das finale Lieferobjekt wird in Iterationen entwickelt und dabei die Zwischenprodukte laufend erweitert. Im agilen Kontext besteht der Anspruch, dass jedes Inkrement einen zusätzlichen Mehrwert für den Auftraggeber – und damit in der Regel für die Endbenutzer eines Systems – schafft. Bei der Entwicklung von BI-Systemen ist dieser Umstand meist dann erfüllt, wenn ein bestimmter Dateninput veredelt wird und dadurch einen höherwertigen Datenoutput erzeugt wird.
Einige Autoren, wie Ken Collier in [Col12], argumentieren, dass nur Inkremente, die „von der Quelle bis zum Datenprodukt“ reichen, wirklichen Mehrwert bieten. Ralph Hughes hingegen behauptet in [Hug13], dass dies in Kombination mit kurzen Iterationen bei grossen Data-Warehouse-Systemen unrealistisch ist. Er schlägt vor, grosse Inkremente in kleinere Entwicklungsaufgaben aufzuteilen, jeweils eine pro Architekturschicht. Wie in [Bra23] erläutert, bin ich der Meinung, dass ein Mittelweg zwischen diesen Extrempositionen zielführender ist. Diesen möchte ich folgend erläutern.
Das Makro-Inkrement
Eine Datenproduktionslinie stellt ein Inkrement dar, wie Collier es beschreibt. Wir nennen es an dieser Stelle ein Makro-Inkrement: Daten aus einer Quelle werden extrahiert, über verschiedene Stufen veredelt und am Schluss in Form eines Datenprodukts dem Endbenutzer zur Verfügung gestellt. Dabei ist wichtig zu berücksichtigen, dass eine Datenproduktionslinie selten alle Daten, die ein BI-System benötigt, berücksichtigt. In einer ersten Produktionslinie werden nur gerade diejenigen Daten aus der Quelle extrahiert und verarbeitet, welche für ein erstes Teilergebnis, oder eben Inkrement, benötigt werden. In der Regel sprechen wir hier von drei vier Tabellen einer bestimmten Datenquellen und ein oder zwei Kennzahlen, welche beim ersten Inkrement in einem Datenprodukt ausgewiesen werden.
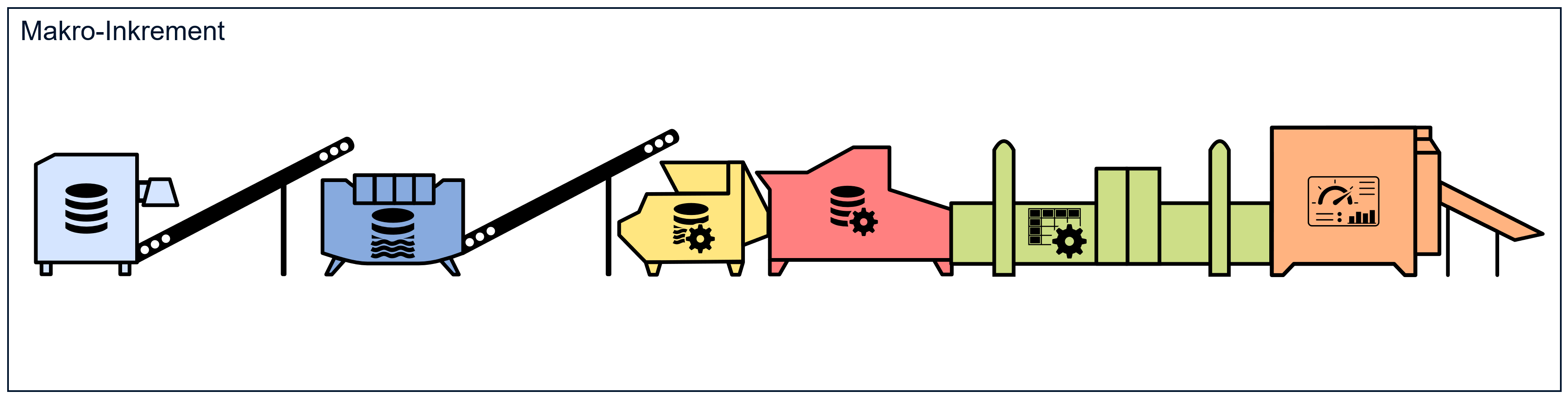
Mikro-Inkremente
In einer idealen Welt könnte ein Entwickler in jeder Iteration mindestens ein solches Makro-Inkrement bauen. Je grösser das Team, desto mehr Makro-Inkremente könnten gleichzeitig realisiert werden. Wie eingangs erläutert würde dies aber den ausschliesslichen Einsatz von Generalizing Specialists bedingen. In Teams jedoch, die primär aus Spezialisten bestehen, müssten einige Spezialisten zuerst die Datenanbindung entwickeln, während die Datenproduktentwickler – etwas überspitzt gesagt – untätig herumsitzen. Hier hilft nun die Analogie des Baus einer Produktionslinie. Der Ablauf des Baus der Produktionslinie orientiert sich dabei an der späteren Struktur der hergestellten Zwischenprodukte. Bei der Datenproduktionslinie lassen sich fünf solche Zwischenprodukte erkennen, welche wir in der Folge Mikro-Inkremente nennen.
Arten von Mikro-Inkrementen
Alle Zwischenprodukte bzw. Mikro-Inkremente zusammen bilden ein Makro-Inkrement:
- Rapid Prototyping
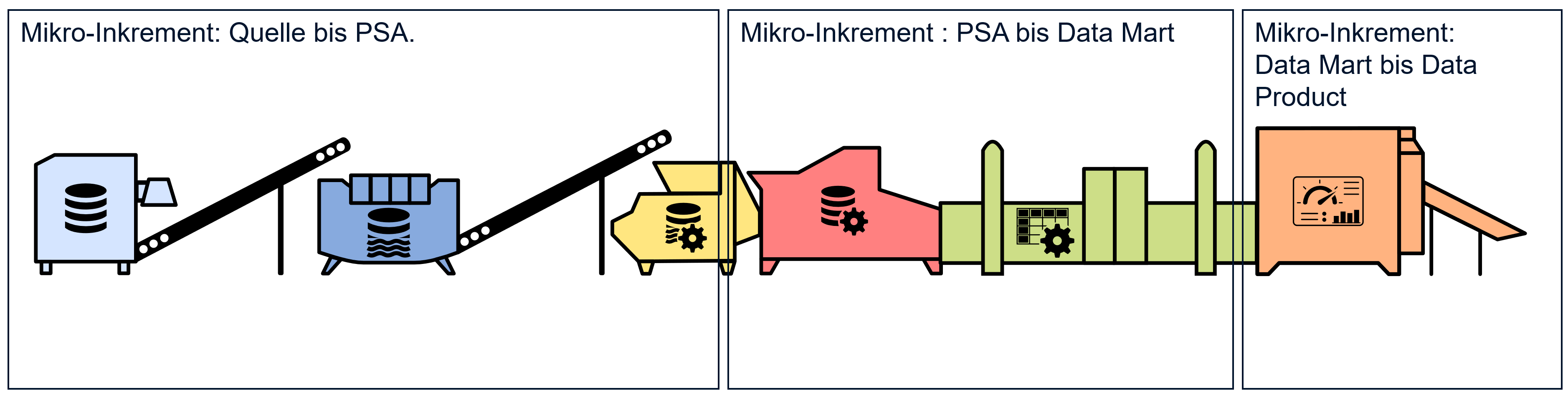
- Quelle bis Datenpersistierer (PSA)
- Datenhomogenisierer (DWH) bis Datenaufbereiter (Data Mart)
- Datenprodukt
- Erhöhung Datenvolumen
Jedes dieser Mikro-Inkremente erfüllt das Kriterium, dass ein (kleiner) Dateninput in einen höherwertigen Output veredelt wird. Jedes dieser Mikro-Inkremente ist folglich demonstrierbar und auch für einen Endbenutzer «greifbar».
Spezialisten und ihr Knowhow
Weiter berücksichtigt dieser «Schnitt» der Mikro-Inkremente die typische Verteilung des Knowhows in einem Team: Während beim Rapid Prototyping verschiedene Spezialisten zusammen experimentieren, lässt sich das Mikro-Inkrement «Quelle bis Datenpersistierer» primär durch Experten mit einem technischen Flair für Datenschnittstellen, Datentypen und Speichersystemen umsetzen. Zudem wird diese Art von Mikro-Inkrement in der Regel mit einem hohen Automationsgrad bei der Datenaufbereitung verbunden. Das Mikro-Inkrement «Datenhomogenisierer bis Datenaufbereiter» bedingt dagegen ein hohes fachliches Verständnis der Anforderungen sowie ausgeprägte Datenmodellierungskenntnisse. Im Mikro-Inkrement «Datenprodukt» wiederum stehen Fähigkeiten zur visuellen Gestaltung und des Data Storytelling im Vordergrund. Beim letzten Mikro-Inkrement, der Erhöhung des Datenvolumens, sind wieder mehr technische Fähigkeiten gefragt, z.B. zur Analyse und Optimierung der Performance der Ladestrecken.
Standardisierung und Datenqualität entlang der Datenproduktionslinie
Produktionslinien ermöglichen durch Standardisierung und integrierte Qualitätskontrolle eine konstante Produktqualität. Diese Prinzipien lassen sich auch auf die Datenproduktionslinie anwenden. Das Rapid Prototyping legt frühzeitig Datenqualitätssicherungsmassnahmen und Akzeptanzkriterien fest. Automatisierung durch Generierung der Ladelogik und standardisierte Tests sind besonders effektiv bei der Datenverarbeitung zwischen Quelle und der PSA.
Für das Mikro-Inkrement der stärker fachspezifischen Schichten des Data Warehouse und des Data Mart ist Expertenwissen erforderlich. Hier werden Geschäftsregeln implementiert und darauf abgestimmte Testfälle entwickelt, die aber nach wie vor automatisiert ausgeführt werden können. Das Datenprodukt wiederum wird unter Berücksichtigung von Best Practices in der Datenvisualisierung und User Experience wie z.B. der IBCS gestaltet. Getestet wird bei diesem letzten Abschnitt der Datenproduktionslinie häufig stichprobenartig und weniger stark automatisiert.
Das letzte Mikro-Inkrement behandelt die Erweiterung des Datenvolumens und das Deployment des gesamten Makro-Inkrements in einer Testumgebung. Dieser Schritt ist sowohl für die finale Qualitätskontrolle als auch für Integrationstests mit bereits bestehenden Systemkomponenten entscheidend.
Den Entwicklungsfluss optimieren
Eines der Ziele eines agilen Entwicklungsteams ist es, die Entwicklungszeit für neue Datenproduktionslinien zu verkürzen und einen kontinuierlichen Fluss von fertigen Makro-Inkrementen zu etablieren, d.h. laufend neue Datenproduktionslinien zu bauen. Gestaltet ein Team bestehend aus Spezialisten seinen BI-Entwicklungsprozess analog einer Produktionslinie, so werden die Spezialisten idealerweise auf fünf «Arbeitsstationen» verteilt, wo jeweils eines der oben beschriebenen Mikro-Inkremente umgesetzt wird. Dabei sind nach einer Anlaufphase bis zu fünf Produktionslinien im Bau: Die zuerst gestartete Produktionslinie befindet sich bereits im erweiterten Datenvolumen-Testing, die zweite befindet sich beim Bau der Datenproduktmaschine, die dritte beim Bau des Datenhomogenisierers und des Datenaufbereiters usw. Dabei gilt es einen Rhythmus zu finden, in welchem die Mikro-Inkremente gebaut werden: Im Idealfall kann jedes Mikro-Inkrement in einem Arbeitstag oder sogar weniger entwickelt werden. Das abschliessende Makro-Inkrement könnte somit nach fünf Arbeitstagen ausgeliefert werden.
Zusammenfassung
Die Betrachtung des BI-Entwicklungsprozesses als Bau einer Datenproduktionslinie bietet mindestens folgende Vorteile:
- Konkret: Durch die Analogie zum Bau der Datenproduktionslinie wird der Prozess – im Vergleich zu abstrakten Architektur- und Prozessdiagrammen – für alle Beteiligten greifbarer und leichter verständlich.
- Agil: Die Einteilung eines Makro-Inkrements in fünf Mikro-Inkremente ermöglicht einen kontinuierlichen Fluss an kleinen, aber dennoch mehrwertstiftenden Lieferergebnissen. Dies fördert wiederum einen stetigen Feedbackfluss zwischen Entwicklern und Endbenutzern und steigert die Agilität des Teams.
- Realistisch: In der Praxis sind Teams oft aus Spezialisten verschiedener Aufgabengebiete zusammengesetzt. Die Analogie zum Bau der Datenproduktionslinie adressiert diese Realität, indem sie spezialisierte „Stationen“ schafft, an denen Teammitglieder ihre Stärken optimal einsetzen können.
Weiterführende Informationen
Das Prinzip der BI- bzw. Datenproduktionslinie haben Jan Riedo und ich am letztjährigen MAKE BI ganz praktisch erläutert (Jetzt anmelden für die Ausgabe 2024 ;-):
Nachstehend finden sich zudem Referenzen zu weiterführender Literatur:
[Bra23] Branger, R.: How to Succeed with Agile Business Intelligence. Oikosofy Series 2023
[Col12] Collier, K.: Agile Analytics. Addison-Wesley 2012
[Hug13] Hughes, R.: Agile data warehousing project management : business intelligence systems using Scrum, Morgan Kaufmann 2013