Business Intelligence (BI)-Projekte haben oft mit langen Entwicklungszyklen zu kämpfen, die die Bereitstellung von Analysefunktionen für Geschäftsanwender verzögern. Die Einführung eines iterativen Ansatzes kann die Agilität deutlich erhöhen. Der Artikel untersucht, wie das Konzept einer «Produktionslinie» den Arbeitsablauf für BI-Teams optimieren kann. Die wesentlichen Aspekte sind dabei der Aufbau der Produktionslinie, die Strukturierung der Arbeit in Makro- und Mikro-Inkremente, die Anwendung von Qualitätssicherungsmaßnahmen entlang der „Produktionslinie“ sowie die Optimierung des Entwicklungsflusses. Die vorgestellte Analogie einer Produktionslinie hilft, den abstrakten Aufbau eines BI-Systems greifbar zu machen und dadurch einfacher zu Optimierungsmassnahmen des Entwicklungsprozesses zu finden.
Der Bau mehrschichtiger BI-Lösungen als Herausforderung
Technische und organisatorische Herausforderungen
Business Intelligence ist mehr als nur ein Instrument zur Datensammlung; es ist ein kompliziertes System, das Daten aus einer oder mehreren Quellen extrahiert und sie über verschiedene Stationen veredelt. (In diesem Artikel beziehe ich mich dabei auf BI-Architekturen der Grösse XL, welche mittels eines systematischen Entwicklungsprozesses umgesetzt werden, siehe dazu [Bra19].) Diese Veredelungsprozesse umfassen eine Vielzahl von Schritten, von der Datenarchivierung und Datenhistorisierung über Löscherkennung, Datenintegration und Datenhomogenisierung bis hin zu Datenmodellierung, Datentransformationen, und schliesslich Datenvisualisierung. Diese Abläufe werden oft in Form von Architekturdiagrammen und verschiedenen Schichten dargestellt, um die Zusammenhänge und Abhängigkeiten sichtbar zu machen.

Abbildung 1 Abstraktes BI-Architekturdiagramm (Quelle: [Bra23])
Der Aufbau eines solchen BI-Systems stellt sowohl technische als auch organisatorische Herausforderungen dar. Technisch gesehen sind die Veredelungsschritte oft eng miteinander verknüpft, was eine Reihe von Abhängigkeiten schafft. So müssen Datenquellen erst erschlossen werden, bevor ein Datenprodukt erstellt werden kann. Organisatorisch gesehen ist die Situation nicht weniger kompliziert. Selten findet man Teams von “Generalizing Specialists”[Amb], in denen ein Einzelner alle Arbeitsschritte zur Datenveredelung ausführen kann. In der Regel bestehen BI-Teams aus einer Reihe von Spezialisten mit unterschiedlichen Fähigkeiten, deren Arbeiten nacheinander erfolgen müssen. So kann beispielsweise ein Experte für Datenmodellierung seine Arbeit erst beginnen, nachdem ein Kollege für die Datenextraktion die erforderlichen Daten bereitgestellt hat.
Der agile Ansatz
Traditionell wurde diese Herausforderung im Wasserfallmodell durch den schichtweisen Aufbau des BI-Systems adressiert. Alle Daten würden zuerst aus einer oder mehreren Quellen extrahiert, danach modelliert, und schliesslich würde ein kompletter Data Mart aufgebaut, bevor es zur Visualisierung kommt. Dieser Ansatz hatte den Nachteil langer Durchlaufzeiten und führte oft zu Frustration, sowohl bei Entwicklern als auch Endbenutzern. Endbenutzer waren in der Regel nur zu Beginn und am Ende des Entwicklungsprozesses involviert, was bedeutete, dass Missverständnisse in den Anforderungen spät erkannt und Chancen für zusätzliche Wertsteigerung verpasst wurden.
Die agile Methodik versucht, diese Schwächen zu adressieren, indem sie den inkrementellen Aufbau des BI-Systems in kurzen Iterationen ermöglicht. Aber was genau ist ein Inkrement in diesem Kontext? Wie kann ein solches Inkrement in nur ein bis zwei Wochen umgesetzt werden? Und wie kann auch einem Fachanwender oder Manager verständlich aufgezeigt werden, dass die Entwicklung eines BI-Systems weit umfangreicher ist als die Entwicklung des schlussendlich sichtbaren Datenprodukts? In meiner Erfahrung waren abstrakte Architekturgraphiken wie in Abb. 1 wenig hilfreich dafür. Daher möchte ich in diesem Artikel die Analogie einer «Datenproduktionslinie» (vgl. dazu [Bra23]) aufnehmen und weiter ausführen.
Der BI-Entwicklungsprozess als Bau einer Datenproduktionslinie
Die Entwicklung eines BI-Systems lässt sich treffend mit dem Bau einer Produktionslinie in einer Fabrik vergleichen. In dieser Analogie entsprechen die verschiedenen Veredelungsschritte einzelnen Maschinen in der Produktionslinie. Als Rohstoff dienen die Quelldaten, die extrahiert werden, und am Ende der Linie entsteht ein fertiges Datenprodukt, etwa ein Dashboard. Einmal korrekt konfiguriert, durchlaufen die Daten diese „Maschinen“ von der Quelle bis zum Endprodukt. In dieser Analogie könnten wir das gesamte BI-System auch als eine Datenfabrik bezeichnen, die aus vielen solchen Produktionslinien besteht.
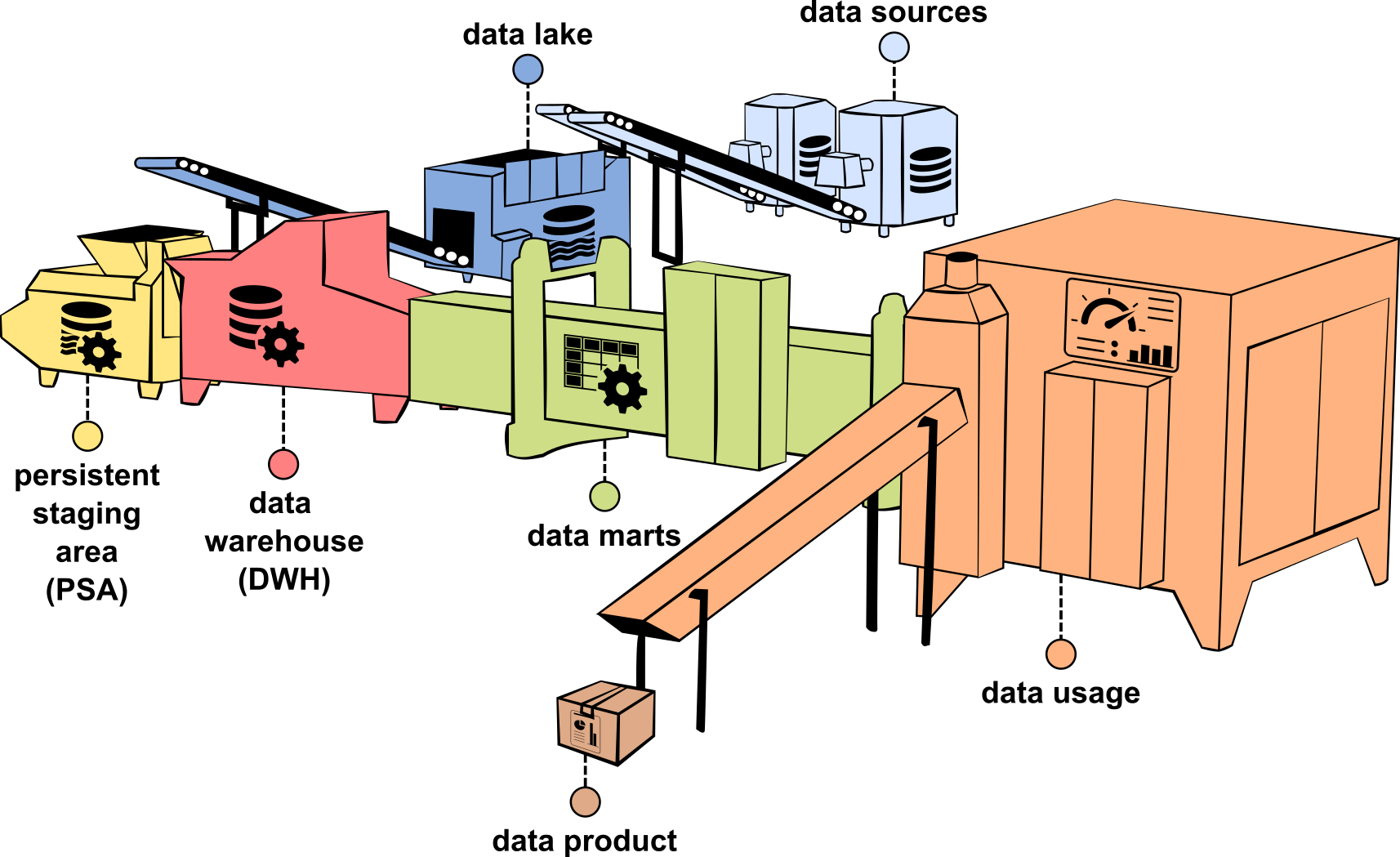
Abbildung 2 Datenproduktionslinie (Quelle: [Bra23])
Prototyping
Bevor die Entwicklung der eigentliche Produktionslinie gestartet wird, gibt es einen vorgelagerten Entwicklungsschritt, der für den möglichst reibungslosen Aufbau der Produktionslinie von entscheidender Bedeutung ist: Das Rapid Prototyping. In einem produzierenden Unternehmen wäre dies die Forschungs- und Entwicklungsabteilung. Hier werden anhand von ersten, manuellen Datenextrakten Mockups von Datenprodukten erstellt und die benötigten Datenquellen profiliert. Basierend auf diesen Erkenntnissen wird die zukünftige Produktionslinie in Form von Arbeitspaketen, den sogenannten Backlog Items, skizziert und Akzeptanzkriterien für deren erfolgreiche Umsetzung festgehalten.
Die Maschinen im „Backend“
Ist die grobe Idee über das zu erstellende Datenprodukt sowie die dafür nötigen Datenproduktionslinien einmal geklärt, wird der Bau der ersten Produktionslinie mit der Installation der ersten Maschine begonnen, einem Datenextraktor. Ein Datenextraktor verfügt über verschiedene Fähigkeiten. Z.B. stellt er eine Verbindung zu einer bestimmten Datenquelle her und kann die Daten daraus extrahieren. Weiter können bestimmte Datenextraktoren erkennen, welche Daten bereits einmal extrahiert wurden und sodann nur neue und geänderte Daten laden. In der «echten» BI-Welt haben Datenextraktoren unterschiedliche Formen, von ODBC-Treibern über Quellsystem-spezifische Extraktionslösungen, hin zu Extraktoren die sich auf die Verbindung via APIs fokussieren oder auf Streaming-orientierte Quellen spezialisiert sind.
Die zweite Maschine in der Produktionslinie übernimmt die Daten vom Datenextraktor und archiviert diese, z.B. in einem Datalake, es handelt sich also um einen Datenarchivierer. Dabei sind die Daten noch mehr oder weniger im Format der Datenquelle und werden eins zu eins so gespeichert.
Die dritte Maschine ist ein Datenpersistierer. In der «echten» Welt entspricht ein Datenpersistierer den Ladeprozessen in eine Persistent Staging Area (PSA). Der Datenpersistierer verfügt dabei über die Möglichkeit, Datensätze anhand von darin enthaltenen Schlüsselfeldern zu historisieren, so dass Änderungen an einem bestimmten Datensatz nicht einfach überschrieben sondern inkl. Zeitstempel der Veränderung nachvollziehbar werden. Zudem kann ein Datenpersistierer auch Datensätze erkennen, welche in der Quelle gelöscht wurden.
Die vierte Maschine ist ein Datenhomogenisierer. Der Datenhomogenisierer bringt nun Daten aus verschiedenen Quellen zusammen. Dazu werden Daten häufig in ein von den Quellen unabhängiges Zieldatenmodell umgewandelt. Der Datenhomogenisierer entspricht in der «echten» Welt den Ladeprozeduren in einer Datawarehouse-Komponente, wo Daten z.B. dimensional oder in Form eines Data Vault Modells abgespeichert werden. Während die bisherigen Maschinen zu grossen Teilen automatisch aufgrund der Datenstrukturen in der Quelle konfiguriert werden können, bedarf der Datenhomogenisierer viel mehr anforderungsspezifischer Konfigurationen. Wenn z.B. Kundendatensätze aus zwei Quellen zusammengeführt werden müssen, so braucht es spezifische Transformationsregeln, damit das System erkennt, ob zwei unterschiedliche Datensätze in Tat und Wahrheit den gleichen Kunden beschreiben.
Die Maschinen im Frontend
Die fünfte Maschine ist ein Datenaufbereiter. Der Datenaufbereiter ist dafür verantwortlich, Daten in einen bestimmten, fachlichen Kontext zu setzen. Dazu werden Daten anforderungsabhängig gefiltert, Kennzahlen anforderungsabhängig berechnet usw. In der echten Welt entspricht der Datenaufbereiter der Data Mart Ebene.
Die sechste und letzte Maschine in unserer imaginären Datenproduktionslinie ist die Datenproduktionsmaschine. Hier werden die Daten aus dem Datenaufbereiter in Form von Tabellen und Diagrammen dargestellt. Oder aber als Schnittstellen anderen Systemen zur Verfügung gestellt.
So wie das Rapid Prototyping zu Beginn der Produktionslinie vorgelagert ist, gibt es auch einen nachgelagerten Schritt. Dieser nachgelagerte Schritt dreht sich um die Erhöhung des Datenvolumens. Während beim Bau der Produktionslinie oft mit kleinen Datenmengen gearbeitet wird, müssen die Maschinen im Anschluss mit der vollen «Datenlast» getestet werden. Dadurch werden hin und wieder Nachkonfigurationen nötig, wenn beim vollen Datenvolumen Datenqualitätsmängel auftreten, die so bei der Entwicklung der Produktionslinie noch nicht sichtbar wurden.
Zusammenfassung und Ausblick
In diesem ersten Teil des Artikels zur „BI-Produktionslinie“ habe ich aufgezeigt, dass der Aufbau mehrschichtiger Business Intelligence (BI)-Systeme technische und organisatorische Herausforderungen mit sich bringt. Während BI-Systeme normalerweise mittels abstrakter Architekturdiagramme illustriert werden, nutze ich die Analogie von Produktionslinien in einer Datenfabrik, um die verschiedenen Komponenten in einem BI-System mit ihren zugehörigen Aufgaben zu illustrieren. Im zweiten Teil dieses Artikels werde ich darauf eingehen, wie man das Bild der Produktionslinie nutzen kann, um die Entwicklungsarbeiten in Makro- und Mikroinkremente zu unterteilen. Zudem werde ich darauf eingehen, was wir uns für eine BI-Produktionslinie von einer „richtigen“ Produktionslinie abschauen können, z.B. hinsichtlich Qualitätssicherung entlang der Produktionslinie oder wie man den Entwicklungsfluss in einem grossen Team optimieren kann.
Weiterführende Informationen
Das Prinzip der BI- bzw. Datenproduktionslinie haben Jan Riedo und ich am letztjährigen MAKE BI ganz praktisch erläutert (Jetzt anmelden für die Ausgabe 2024 ;-):
Nachstehend finden sich zudem Referenzen zu weiterführender Literatur:
[Amb] Scott, A.: Generalizing Specialists: Improving Your Effectiveness. http://agilemodeling.com/essays/generalizingSpecialists.htm
[Bra19] Branger, R.: T-Shirt-Größen für BI-Lösungen. In: BI-Spektrum 3-2019, S. 33 – 37
[Bra23] Branger, R.: How to Succeed with Agile Business Intelligence. Oikosofy Series 2023