Einleitung und Anwendungsfall
Vorbei sind die Zeiten, wo man es sich leisten konnte, erst nach vielen Monaten oder sogar Jahren der DWH-Entwicklung eine brauchbare Lösung zur Verfügung zu stellen. Zeit ist bekanntlich Geld und daher kostbar. Auf der Methodenseite bieten sich häufig agile, d.h. iterativ-inkrementelle Vorgehen an, um diesem Umstand zu begegnen. Sie finden in einigen früheren Artikeln von mir bereits zahlreiche Ausführungen dazu. In diesem Artikel möchte ich nun erläutern, welche Rolle Werkzeuge aus der Kategorie «DWH Automation» haben. Das möchte ich anhand eines praktischen Beispiels illustrieren.
Der Anwendungsfall ist folgender: Die Firmen Xtreme und Northwind sind ein Joint Venture («XtremeNorth») eingegangen und möchten nun so rasch wie möglich ein gemeinsames, firmenübergreifendes Reporting etablieren. Dabei greifen sie als Quellen auf ihre jeweiligen ERP-Systeme zurück, wobei die Daten jeweils in einer SQL-Server Datenbank liegen. Um möglichst rasch zu einem ersten Ergebnis zu kommen, setzen die beiden Firmen auf die DWH-Automationslösung «WhereScape RED».
In einer ersten Iteration sollen Bestelldaten («Orders») ausgewertet werden entlang der Zeitdimension sowie nach Produkten und Kunden. Das Core-Warehouse wird dimensional modelliert.
DWH-Automation mit WhereScape RED
WhereScape RED basiert auf dem ELT-Prinzip. D.h. in einem ersten Schritt werden die benötigten Daten aus den Quellsystemen in das Zielsystem, der DWH-Datenbank, geladen. Dort werden die Daten bei Bedarf noch weiter transformiert. Der erste Schritt in WhereScape RED ist die Erstellung von Loadtabellen. Diese werden dadurch erstellt, dass man Tabellen aus dem «Source-Browser» in die eigentliche Arbeitsfläche von RED zieht:
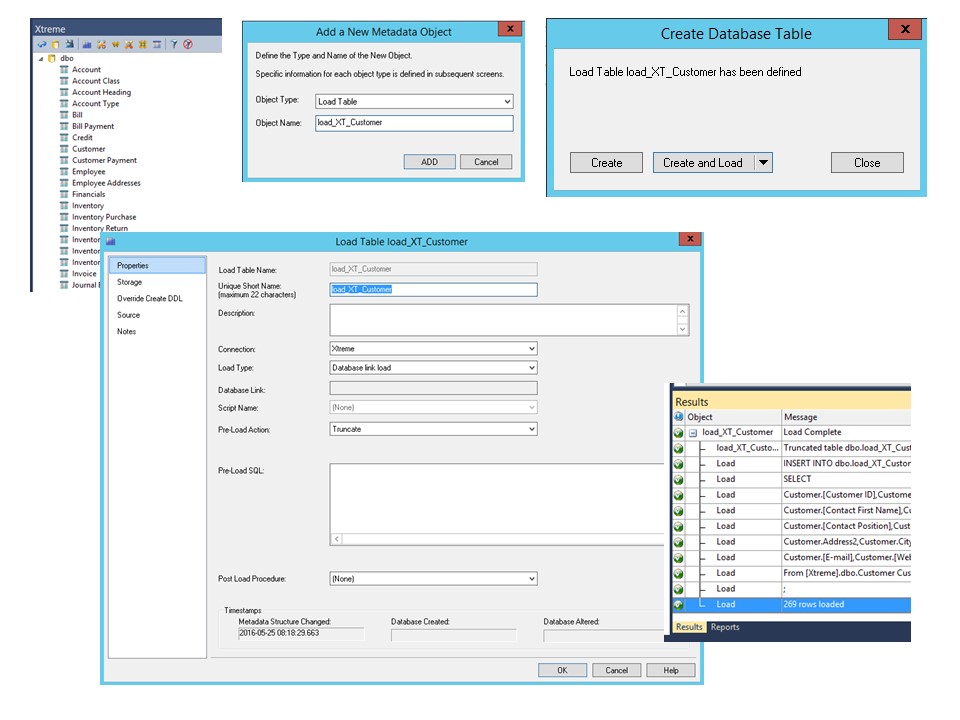
Mit wenigen Klicks erstelle ich in der Folge die nachstehenden Load-Tabellen:
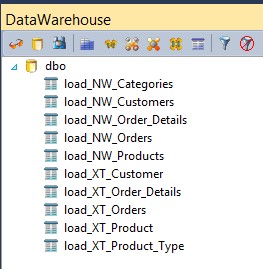
Um die beiden Quellsysteme besser unterscheiden zu können, habe ich bei der Namensgebung entsprechende Kürzel (NW, XT) verwendet.
Der nächste «Layer» im XtremeNorth-DWH ist ein Viewlayer, um die Daten der beiden Firmen zu integrieren. In dieser ersten Iteration wird vorerst auf inhaltliche Konsolidierung verzichtet, d.h. es gibt noch kein einheitliches Stammdatenmanagement z.B. der beiden Kundenstämme. Mittels UNION-Views werden die Daten zusammengefügt:
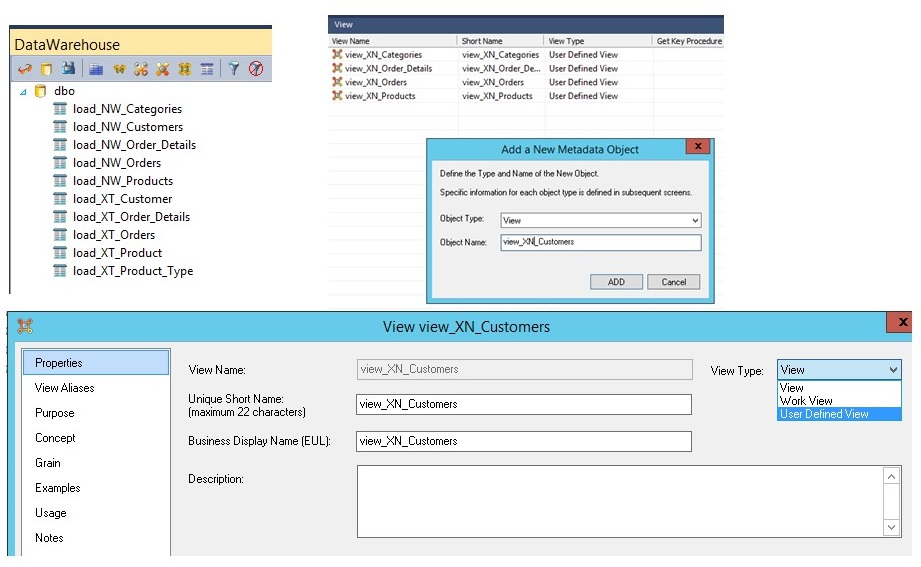
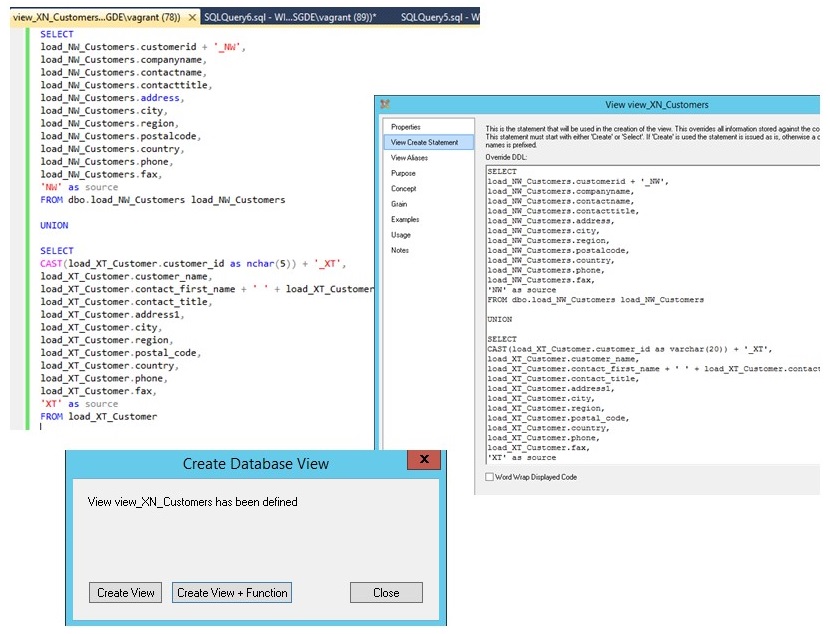
In der UNION-View mache ich einige inhaltliche Transformationen, z.B. stelle ich sicher, dass der Businesskey (im Beispiel customerid) für beide Systeme eineindeutig ist. Ebenso werden Datentypen transformiert, wo diese in den jeweiligen Quellsystemen unterschiedlich sind.
Im nächsten Schritt erstelle ich die Dimensions-Objekte, z.B. die Kundendimension auf Basis der vorher erstellten View:
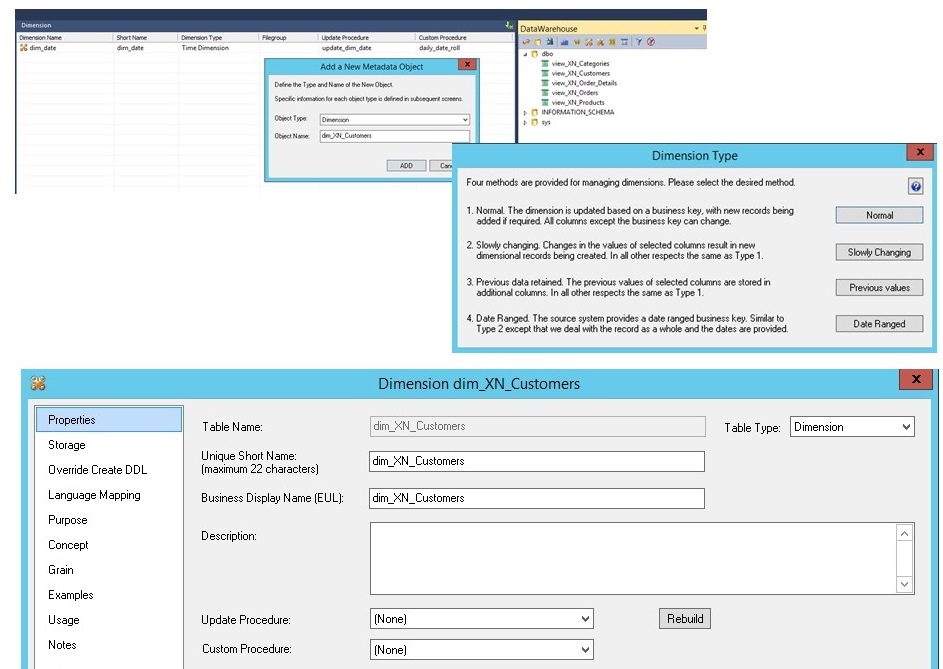
WhereScape RED fragt dabei ab, ob die Dimension historisiert werden soll, was ich zurzeit nicht benötige. Anschliessend wird die eigentliche Ladeprozedur erstellt. Dazu muss ich in erster Linie den Businesskey spezifizieren – alles Weitere übernimmt WhereScape, u.a. das Anlegen eines Surrogatekeys:
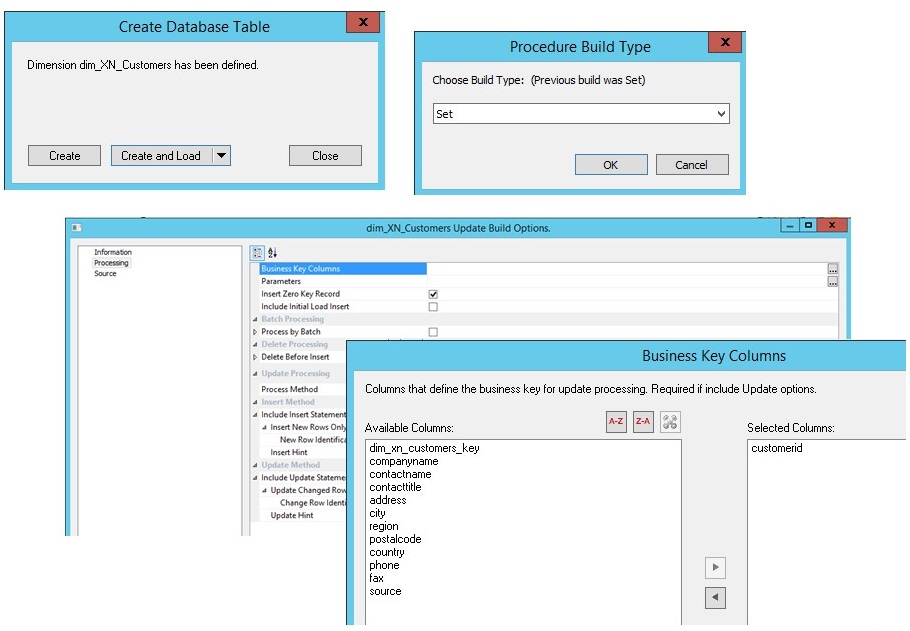
Die gleichen Schritte wiederhole ich für die Produktdimension (die Datumsdimension steht im Übrigen standardmässig zur Verfügung).
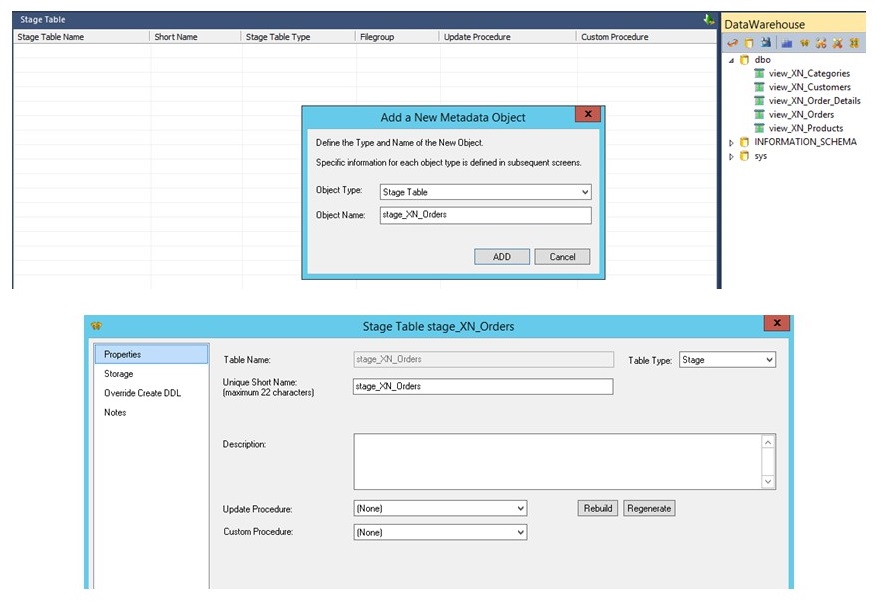
Anschliessend an die Erstellung der Dimensionen wird eine Stage-Tabelle benötigt, um die eigentlichen Fakten aufzubereiten (Verknüpfung von Orders und Order-Details) und die Verknüpfung mit den Dimensionen zu vollziehen:
Zuerst werden die benötigten Felder aus der Orders- und Order-Details-Tabelle in den Arbeitsbereich gezogen, um die neue Stage-Tabelle zu erstellen.
Anschliessend muss der Join zwischen diesen beiden Tabellen spezifiziert werden:
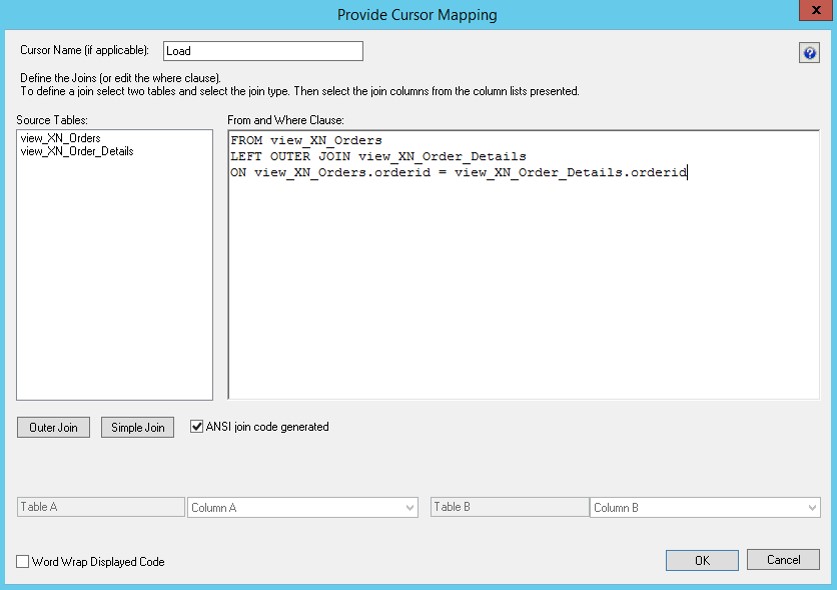
Durch Drag n’Drop werden die Dimensionen hinzugefügt, wobei nur der Surrogatekey in die Stagetabelle hinzugefügt wird – die Verknüpfung spezifiziere ich auf Basis der Business Keys:

Kennzahlen (z.B. das Liefergewicht der Bestellung), welche ihren Ursprung in der Orders-Tabelle haben, werden durch den Join mit den Order-Details möglicherweise multipliziert (für Bestellungen mit mehr als einer Bestellposition). Entsprechend muss diese Kennzahl über eine kleine Transformation korrekt berechnet werden:
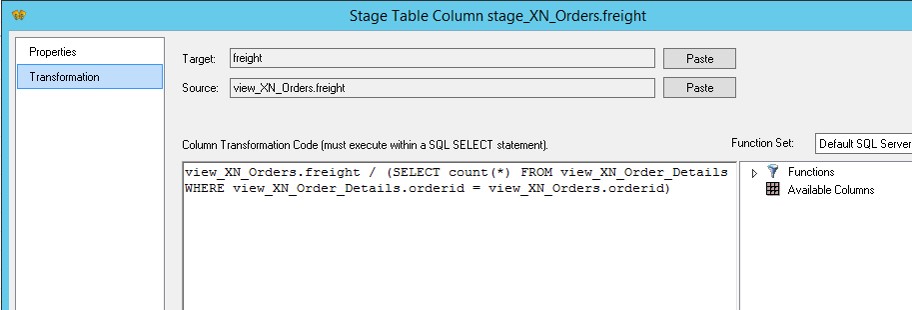
Aus der Stage-Tabelle kann ich nun im Handumdrehen die Faktentabelle erstellen:
Um die Daten noch etwas handlicher abfragen zu können, erstelle ich einen OLAP-Cube (in diesem Fall auf Basis von SQL Server Analysis Services):
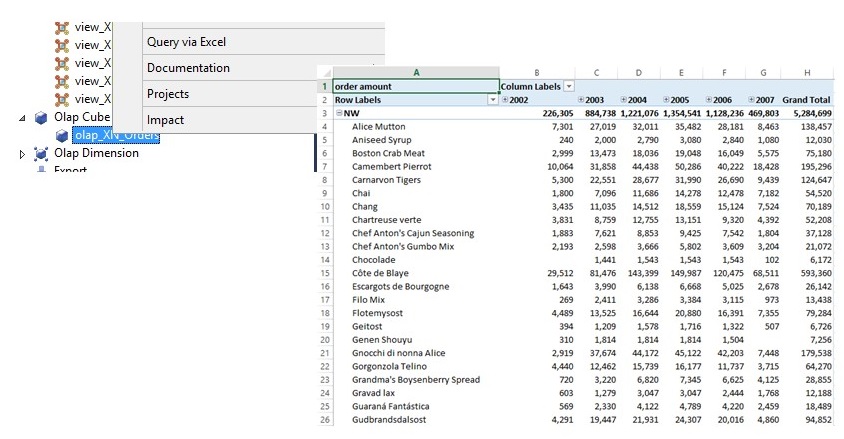
Dann wollen wir mal schauen, was dabei rausgekommen ist:
Fazit
WhereScape ist nicht nur eine zweckneutrale «ELT Toolbox», um Daten von A nach B zu schieben. Aufgrund eines inhaltlichen Verständnisses eines Datawarehouse (z.B. von Dimensionen und Fakten), werden auch entsprechende Design Patterns für Automation der Erstellung und Befüllung dieser Strukturen angeboten. Dadurch lässt sich die Entwicklungszeit massiv reduzieren, in unserer Erfahrung je nach Aufgabe zwischen 20 – 40%!
Im nächsten Artikel werde ich dann erläutern, wie die Lösung von einem Entwicklungssystem auf ein Test- und Produktionssystem verteilt werden kann.