Der Modellierungsansatz Data Vault steht bei vielen Unternehmen aktuell hoch im Kurs. Sucht man nach Gründen wird man schnell fündig. Wer sich über Data Vault informiert, erhält viele Versprechen wie «kann automatisch erstellt werden», «kann beliebig erweitert werden», «die Modellierung erfolgt nach der Realität des Fachbereiches». In diesem Beitrag möchte ich diese genannten Vorteile auf den Prüfstand stellen und aufzeigen, welche Punkte man beobachten muss, wenn man ein Data Vault Projekt umsetzen möchte.
Data Vault (DV) ist eigentlich ein einfaches Konzept. Nach dem Lesen eines Buches, wie z.B. von Dan Linstedt oder auch nach dem Besuch eines Ausbildungsworkshops hat man das Grundprinzip mit den Hubs, Links und Satelliten verstanden und alles erscheint logisch und einfach.
Dann geht es los mit dem ersten DV-Projekt und man befolgt die Schritte, welche man gelernt hat. Doch schon bald stellen sich die ersten konzeptionellen Fragen, auf welche man keine Antwort hat, wie z.B.:
- Welche technische Architektur soll angewendet werden?
- Wie gehe ich vor, wenn die Aussagen des Fachbereichs nicht mit den Daten zusammenpassen?
- Wie gehe ich mit Datentransformationen um und wo in der Architektur wende ich diese an?
- Was mache ich, wenn kein eindeutiger Business Key vorhanden ist?
Diesen und weiteren konzeptionellen Fragen begegnet man sehr schnell bei der Umsetzung des ersten Projekts. Antworten auf diese Fragen erhält man jedoch erst durch die Sammlung von eigenen praktischen Erfahrungen. Gerne möchte ich nachfolgend ein paar Themen aufgreifen und meine praktischen Erfahrungen teilen.
Die klassische DWH-Architektur besteht aus Load / Stage Bereich zur Vorbereitung der Daten, dem «Core», welcher als zentraler Datenspeicher des DWHs gilt und einem Business / Data Mart Bereich, welche die Daten so aufbereitet beinhaltet, dass der Fachbereich diese auswerten kann. Eine DV-Architektur ist grundsätzlich identisch aufgebaut, jedoch werden zwei Bereiche anders verwendet. Der grosse Unterschied zu den klassischen Methoden (z.B. Kimball) besteht darin, dass im Rahmen des Stage Layers keine Business Logik angewendet wird und somit keine Daten transformiert werden. Die Datentransformation wird erst im Rahmen des Core stattfinden, welcher dafür in zwei Sub-Layer unterteilt wird, den Raw Vault und den Business Vault.
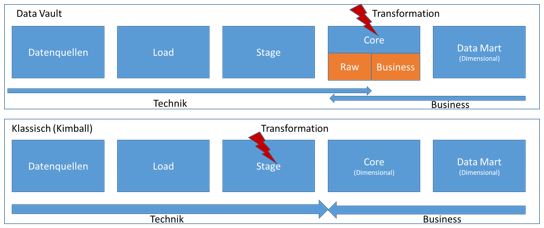
Diese Änderung an der Architektur unterstützt Data Vault dabei, den Fokus bis in den Core auf die technische Verarbeitung und damit wiederholbaren Mustern zu legen. Auf Basis dieser Grundlage und den zusätzlichen Anpassungen an der Modellierung, wie das Separieren aller Modellbestandteile in eigenständige Elemente (Hub, Link und Satellit), erlaubt die Anwendung von ständig wiederkehrenden Vorgängen und damit der Automatisierung davon.
Die Frage stellt sich nun, ob Automatisierung auch gleichbedeutend mit schnell ist?
Aus der Erfahrung von BI-Projekten wissen wir, dass einer der grössten Zeitfaktoren die Business Analyse bzw. die Anforderungsaufnahme darstellt. Gleichzeitig wissen wir aber auch, dass ein korrektes Verständnis der Businessprozesse und den damit verbundenen Daten einer der wichtigsten Erfolgsfaktoren für ein erfolgreiches DWH bedeutet. Betrachtet man nun Data Vault, die vorher beschriebene Architektur und die Versprechen diesbezüglich, dann passt das alles nicht so wirklich zusammen. Einerseits wollen wir nahe am Business sein, und dies kostet ja viel Zeit. Auf der anderen Seite schieben wir die Business Logik in der Architektur nach hinten damit es schneller gehen sollte. Es stellt sich somit die Frage, ob man nun die Businessnähe oder die Geschwindigkeit ins Zentrum stellt.
Business Driven vs. Source Drive
Wichtig für das Verständnis der DV-Architektur ist hierbei, dass auch der Raw Vault nicht eine reine Abbildung der Quellsysteme ist. Der Data Vault selber soll, wie auch bei Kimball, bereits eine Abbildung der Business-Zusammenhänge darstellen. Dies bedeutet, dass die Hauptaufgabe darin liegt, dass die Abbildung der Geschäftsprozesse mit ihren Entitäten auf den jeweiligen Business Schlüsseln basiert und nicht auf technischen Schlüsseln, welche die Quellsysteme liefern. Das Versprechen von DV näher am Business zu sein, kommt zu einem grossen Teil genau aus diesem Vorgehen. Die Bestimmung der korrekten Business Schlüssel, sowie den Entitäten der Geschäftsprozesse, stellt die grosse Herausforderungen bei der Modellierung dar und bedingt daher den engen Austausch mit den Fachbereichen. Dies passt somit zum ersten Abschnitt, in welchem darüber gesprochen wurde, dass dies einer der grossen Erfolgsfaktoren ist. Jedoch führt dies gleichzeitig auch dazu, dass viel Zeit in diese Abstimmung investiert werden muss und somit das Thema «schnell» nicht direkt erfüllt wird. Dieser «Business Driven» Approach zum Aufbau eines Data Vault führt dazu, dass man in den ersten Projekten oft ernüchtert feststellt, dass die Geschwindigkeit zur Umsetzung von Anforderungen nicht erfüllt wird.
Meine Erfahrung in Projekten ist, dass man dann dazu tendiert, den Data Vault in erster Linie sehr nahe an den Quellsystemen zu orientieren, um diesem Umstand entgegenzutreten. Dieser Source Driven Approach wird auch durch Automatisierungslösungen begünstigt, weil es einfach ist, über ein Reverse Engineering der Source Systeme die Verbindungen herzustellen und diese dann über die DV-Templates automatisiert in den Raw Vault zu integrieren.
Dieses Source Driven Vorgehen erfüllt sicherlich die Anforderung an die Geschwindigkeit der rein technischen Integration. Jedoch führt es dazu, dass wir die Businessnähe vor allem durch Transformation zwischen Raw und Business Vault erschlagen müssen. Dies führt direkt zu komplexeren Modellen und somit zu einem Risiko, dass das DWH irgendwann nicht mehr verstanden wird oder bei Ablösungen von Quellsystemen ein grosser Aufwand zum Überarbeiten entsteht. Zusätzlich erfüllen wir damit nicht den Anspruch von Data Vault, eine Integration über Business Keys zu erreichen.

Grundsätzlich gilt somit zu sagen, dass beide Ansätze positive wie auch negative Aspekte haben. In der Vergleichs-Tabelle 1 sehen wir, dass die Automatisierung bis in den Raw Vault in beiden Fällen gegeben ist, da die DV-Patterns mit Hub, Link und Satellit in beiden Fällen angewendet werden können. Die Frage der Geschwindigkeit «schnell» ist somit nicht in erster Linie eine Frage der Automatisierung der Implementation, sondern der Methode, welche angewendet wird.
Aus meiner Sicht gibt es aber einen anderen Vorteil, welcher viel wichtiger ist als das Thema «schnell». Die Qualität!
Die Erfahrung zeigt, dass es selten möglich ist, in einem ersten Durchlauf bereits das ideale Businessverständnis zu erlangen. Daher ist ein iterativer Vorgang notwendig, um in mehreren Überarbeitungen immer näher an die ideale Implementierung zu gelangen. Eine Automatisierung der Implementierung erlaubt mir hierbei, ohne grosse Aufwände mehrere Iterationen umsetzen zu können. Hierbei wird ersichtlich, dass wir vielleicht in der Durchlaufzeit nicht «schneller» sind, jedoch in der gleichen Zeit viel mehr Iterationen, damit verbunden viel mehr Businessnähe schaffen, und somit direkt zu mehr Qualität gelangen.
Die Qualität wird zusätzlich gesteigert, da die Implementation bis in den Raw Vault immer komplett identisch erfolgt und somit keine Abweichungen durch unterschiedliche Entwickler und Ähnliches auftreten können.
Fazit / Empfehlung
Wie bei vielen Themen im Bereich Business Intelligence gibt es auch für die Anwendung von Data Vault nicht die EINE korrekte Lösung. Es gilt, die Möglichkeiten abzuwägen und für sich die korrekte Balance, im Sinne dieses Beitrags zwischen Geschwindigkeit und Businessnähe, zu finden. Um ein gutes Verständnis zu erlangen, sollten die verschiedenen Ansätze unbedingt ausprobiert werden. Denn nur so erfährt man die Vor- und Nachteile im Detail und kann sich wirklich ein Urteil bilden.
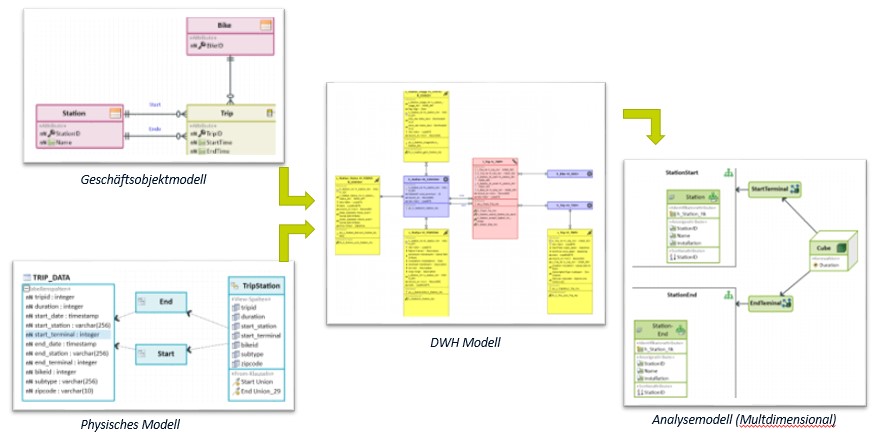
Meine Empfehlung betreffend des Vorgehens basiert heute, so richtig schweizerisch, auf einem Kompromiss. Ich empfehle in den ersten Iterationen Source Driven vorzugehen, um möglichst schnell ein Analysemodell zu erhalten, welches ich dann in den Workshops mit den Fachpersonen verwenden kann. Dadurch erlange ich schneller ein gemeinsames Verständnis mit dem Fach und kann die korrekten Business Schlüssel ableiten und ein Geschäftsobjektmodell ableiten. Darauf basierend erstelle ich in weiteren Iterationen mein überarbeitetes DWH-Modell.
Um dies effizient durchführen zu können, muss ich meine DV-Architektur entsprechend aufbauen, dass ich in der Lage bin, den DV immer wieder neu zu erstellen. Ein aktuell sehr viel diskutiertes Thema (z.B. von Roelant Vos http://roelantvos.com/blog/?tag=data-vault) ist hierbei die Persistent Stage Area (PSA), welche erlaubt, dass ich den DV immer wieder neu modellieren und aufbauen kann bzw. sogar in einem weiteren Schritt die Möglichkeit habe, den DV rein virtuell (Virtual DWH) zu erstellen. Mehr dazu und den Erfahrungen in einem der nächsten Beiträge.