Ein wichtiger Schritt in Hinblick auf die optimale Nutzung Ihrer Daten bzw. Ihres DWH: Nutzen Sie statistische Methoden, um sicherzustellen, dass Ihre Daten die notwendige Qualität aufweisen, um Ihre Business-Fragen zu beantworten.
Wie können Sie vermeiden, dass komplexe Datenanalysen irreführende oder falsche Resultate zu Tage bringen und so genau das Gegenteil vom ursprünglichen Ziel bewirken? Neben den klassischen Data Quality Prozessen wie Data Cleansing, Konsistenzprüfungen und Datenstandardisierungsprozessen via Business-Rules sollten Sie die Nutzung von ausgeklügelten statistischen Algorithmen in Betracht ziehen. Damit stellen Sie sicher, dass Ihre Daten sowohl akkurat (inhaltlich richtig), wie auch verfügbar (die wichtigen Informationen sind in den Daten enthalten) sind.
Data Accuracy and Data Availability
Data accuracy bedeutet, dass die gespeicherten Daten inhaltlich richtig sind. Oft werden durch Eingabefehler des Benutzers oder durch fehlerhafte Backend-Prozesse diesbezüglich Fehler produziert. Dergestalt fehlerhafte Daten haben folgeschwere Auswirkungen für nachgelagerte Datenanalysen, insbesondere bei Vorhersagen und Projektionen.
Data availability bedeutet, dass alle notwendigen Daten (-ausprägungen) verfügbar sind, um die gewünschten (sowohl aktuellen, wie auch zukünftigen) Analysen durchführen zu können. Die Verfügbarkeit von externen Daten und die analytischen Möglichkeiten haben die Möglichkeiten von datengetriebenen Geschäftsprozessen exponentiell vergrössert. Um die Vorteile daraus zu realisieren, ist es unumgänglich, die Daten systematisch in einem Warehouse/Lake zu speichern und entsprechend verfügbar zu machen.
Beurteilung der Data Accuracy
Statistische Analyse und Tests
Will beispielsweise ein Detailhändler die Zeitstempel von Online-Bestellungen überprüfen, kann die statistische Analyse von grossem Nutzen sein. In Abbildung 1 ist erkennbar, dass alle 10 Minuten eine Anomalie in den Bestellungen vorkommt. Wieso können wir sagen, dass dies eine Anomalie ist? Statistisch betrachtet besteht nur eine 0.01% Wahrscheinlichkeit, dass in solcher Regelmässigkeit solche Ausreisser vorkommen. Daraus können wir ziemlich verlässlich schliessen, dass der Zeitstempel – Mechanismus überprüft werden muss.
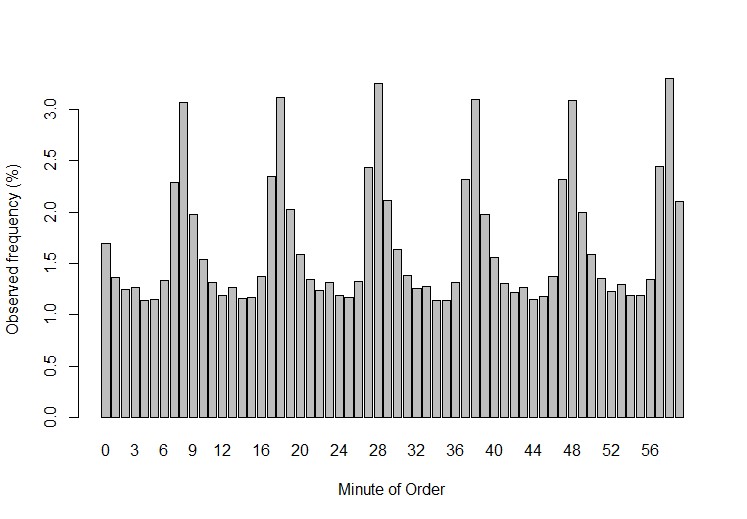
Abbildung 1: Anzahl Bestellungen pro Minute eines Online-Händlers. Die statistischen Anomalien können alle 10min beobachtet werden und deuten auf ein Datenqualitätsproblem hin.
Ausreisser-Erkennung via statistische Modelle
Datenausreisser sind oft verbunden mit Data Accuracy-Problemen. Daher ist eine automatische Erkennung ebensolcher sehr wichtig. Bis heute werden oft einfache Geschäftsregeln verwendet, um solche Ausreisser zu erkennen (z.B. Unter-/Obergrenze, rollierender Durchschnitt, etc.).Diese können jedoch zu ungenau sein, da komplexere Vorkommnisse nicht abgedeckt werden (Saisonalität, Trends). Mittels statistischen Methoden wie z.B. Regressionsmodellen werden Ausreisser automatisch und präziser erfasst, da die Muster in den Daten berücksichtigt werden. In Abbildung 2 werden Dateneingaben abgebildet, welche genauer untersucht werden müssen, da sie vom absteigenden Trend des Regressionsmodells abweichen, jedoch nicht von den Geschäftsregeln «entdeckt» werden.
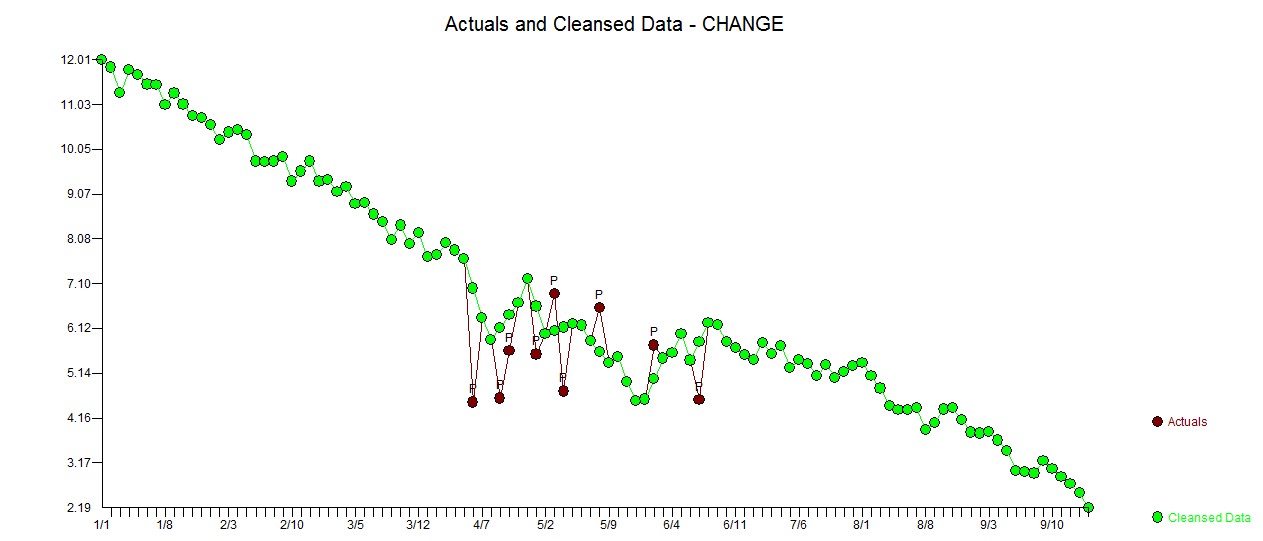
Abbildung 2: Das Modell entdeckt Dateneingaben, welche möglicherweise Ausreisser sind (in rot), obwohl sie noch innerhalb der Geschäftsregel liegen.
Beurteilung der Data Availability
Es ist heute für Firmen unternehmenskritisch, dass die richtigen Daten verfügbar sind, um wichtige Business-Fragen zu beantworten. Dank moderner Datenanalysen können wir quantifizieren, wie gut solche Fragen beantwortet werden können. Dazu werden die vorhandenen Daten aus den Fachapplikationen analysiert und bei Bedarf mit externen Daten angereichert.
Information gain and explained variance
Szenario: Ein Detailhändler möchte eine Umsatzprognose auf Tagesbasis für ein bestimmtes Produkt erstellen. Eine solche Prognose basiert normalerweise auf Daten wie: Vergangene Verkaufsdaten, Kalenderdaten, Marketingdaten, Wetterdaten, etc. Doch wie stark tragen die einzelnen Datenquellen zu der Richtigkeit der Vorhersage bei? Haben wir sämtliche notwendigen Daten im firmeneigenen DWH oder müssen wir weitere Informationen beschaffen?
In Abbildung 3 wird aufgezeigt:
- Welche Attribute wie wichtig für die Vorhersage der Verkaufsergebnisse sind.
- Wie gut die vorhandenen Attribute geeignet sind, um ein mathematisches Modell für die Verkaufsprognose zu erstellen.
- Wie gross die durchschnittliche Fehlerquote im Prognosemodell ist und wie viele Informationen wir brauchen, um diesen Wert gegen 0 bewegen zu können.
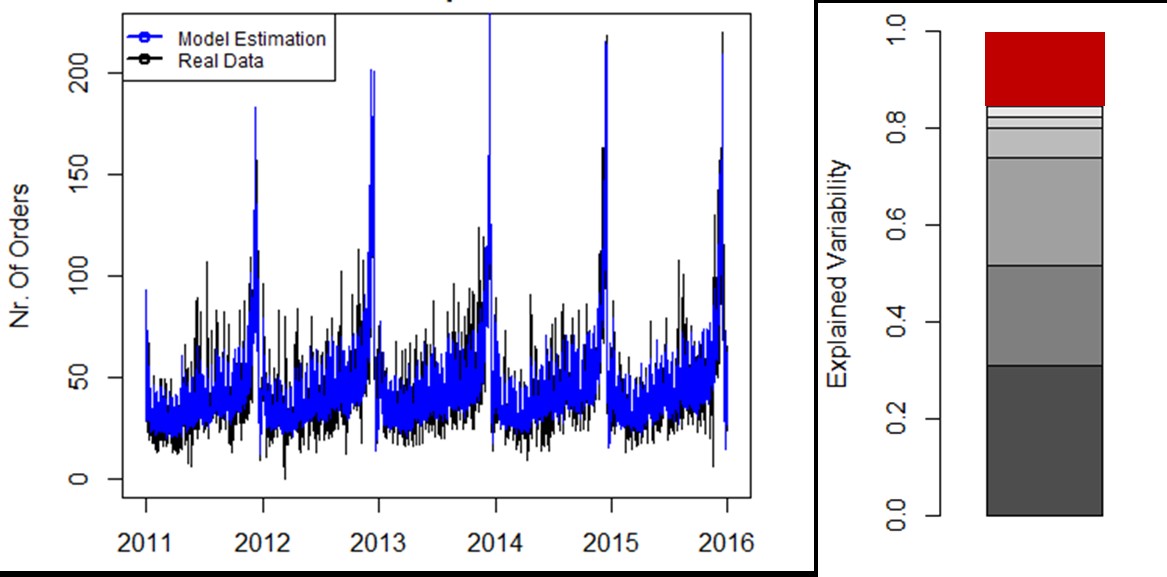
Abbildung 3: Quantifizierung der erklärbaren Varianzen im Prognosemodell von Verkaufsdaten. 6 Attribute (grau) erklären 85% der täglichen Verkaufsvarianzen. 15% der Varianz (rot) bleibt unerklärt.
Anforderungen & Bedingungen
- Es muss keine Software gekauft werden. Die Berechnungen werden mit R durchgeführt, einer open-source Programmiersprache mit über 7000 Funktionsbausteinen für Datenanalysen.
- Die Datenanalyse kann sowohl on-premise wie auch in der Cloud durchgeführt werden (z.B. Microsoft Azure).
- Eine Geheimhaltungsvereinbarung muss unterzeichnet werden.