In meinem letzten Blog habe ich Ihnen einen Überblick zur Optimierung von BI / DWH Systemen [Link] gegeben. In meinem heutigen Blog beschreibe ich Ihnen das konkrete Vorgehen, wie man einen SAP Data Services ETL Job mit Hinblick auf Performanceprobleme analysiert.
Wie im letzten Blog beschrieben, benötige ich hierzu verschiedene Zugriffe und Tools. Im konkreten Fall von SAP Data Services sind das diese:
- Zugriff auf den SAP Data Services Designer und die Management Console
- Zugriff auf die Datenbank mittels einem SQL Tool
- Zugriff auf eine Entwicklungs- oder Testumgebung mit produktiv(-nahen) Daten
- SQL Session-Überwachungstool zur Laufzeit (z.B. SQL Server Activity Manager)
- Anzeigen von SQL-Ausführungsplänen
- Zugriff auf den DB- und ETL-Server zur Laufzeit, um CPU, RAM und Netzwerkauslastung zu überwachen
Schritt 1: Analyse vergangener Job Ausführungen
Der Einstiegspunkt für die Analyse ist die SAP Data Services Management Console. Hier finde ich alle Ausführungen jedes einzelnen ETL Jobs und die dazugehörigen Trace-, Monitor- und Error-Logs.
Um alle Ausführungen eines Jobs zu finden, kann man wie unten im Screenshot dargestellt, nach einem spezifischen Job suchen.
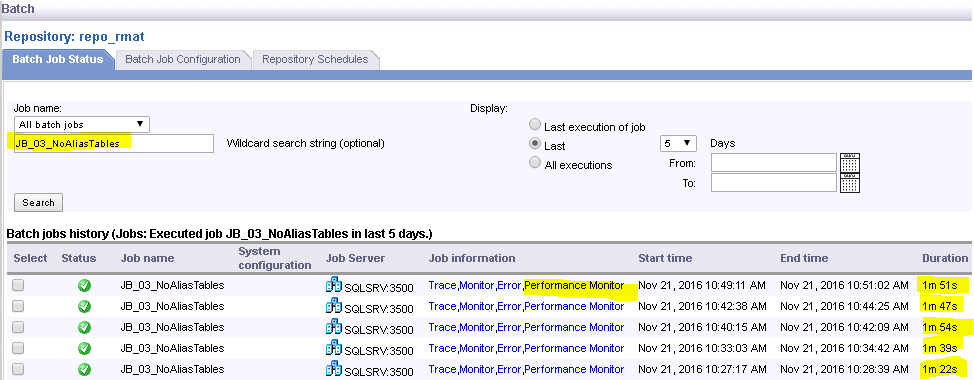
Sind die Ausführungszeiten bei gleichbleibender Anzahl der verarbeiteten Records (im Monitor Log zu finden) sehr unterschiedlich, deutet das oft darauf hin, dass das Netzwerk, die Datenbank oder der SAP Data Services Server als Ganzes während der Verarbeitung überlastet ist (z.B. zu viele Jobs, welche parallel laufen). Wäre das der Fall, würde ich zur Laufzeit der Jobs auf dem SAP Data Services Server und auf dem Datenbank Server den Task Manager starten und die Auslastung des Systems als Ganzes betrachten.
Ist dies nicht der Fall, suche ich über den Performance Monitor, den Datenfluss, welcher am längsten läuft.

Ist der «Langläufer-Datenfluss» identifiziert, öffne ich den SAP Data Services Designer und gehe wie folgt vor:
Schritt 2: Analyse der Anti-Patterns
Gibt es irgendwelche Anti-Patterns (vgl. dazu meinen nächsten Blog zum Thema Top Anti-Patterns in SAP Data Services [Link])? Falls Anti-Patterns existieren, werden diese entfernt. Falls es keine Anti-Patterns gibt und der Datenfluss trotzdem langsam ist, geht die Analyse weiter.
Schritt 3: Analyse der Quelldaten Selektionen – First Rows
SAP Data Services ist ein Applikationsserver und ist selten auf demselben Server wie die Datenbank installiert. Die Daten müssen deshalb meist über ein Netzwerk aus der Datenbank gelesen und zum SAP Data Services Server transferiert werden. Um auszuschliessen, dass die Quellselektion der Datenbank einen Engpass darstellt, prüfe ich zuerst, wie gut die SQLs auf der Quelldatenbank laufen, welche SAP Data Services zur Laufzeit des ETL Jobs an die Datenbank abschickt. Die SQLs,welche an die Quelldatenbank geschickt werden, können in SAP Data Services via dem Menu Punkt „…Display optimized SQL“ angezeigt werden.
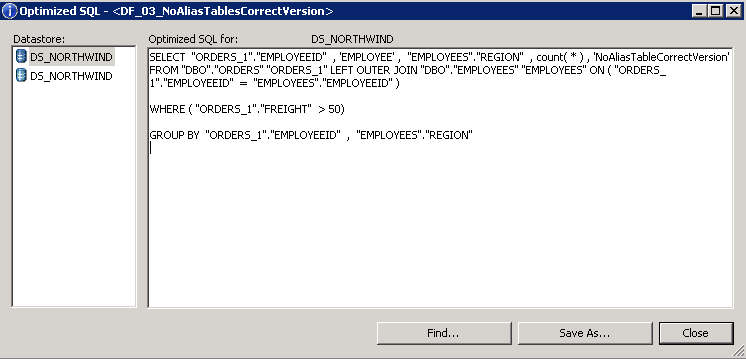
Diese SQLs werden dann im SQL Tool ausgeführt, dann wirdals Erstes geschaut, wie schnell First Rows bzw. ein Top 1000 * Select dauert.
- Falls First-Rows-Daten nicht innerhalb von wenigen Sekunden zurückgegeben werden, sollte das SQL optimiert werden, das an die Datenbank geschickt wird. Dies kann über Indexierung der Quelltabellen und/oder dem Anlegen von Datenbankstatistiken und/oder durch Redesign des SAP Data Services Dataflows geschehen (um ein anderes SQL zu erzeugen).
- Welche Indexe auf der Datenbank verwendet werden bzw. welche Statistiken fehlen, kann über den Ausführungsplan herausgefunden werden. Mehr Infos zu SQL Server: https://technet.microsoft.com/de-de/library/ms178071(v=sql.105).aspx
Das Lesen und Interpretieren von Ausführungsplänen erfordert etwas Erfahrung des jeweiligen Datenbanksystems. Beim SQL Server werden jedoch bereits Vorschläge gegeben, was allenfalls eine verbesserte Performance bringen könnte. Beim SQL aus dem obigen Beispiel sieht der Ausführungsplan wie folgt aus:
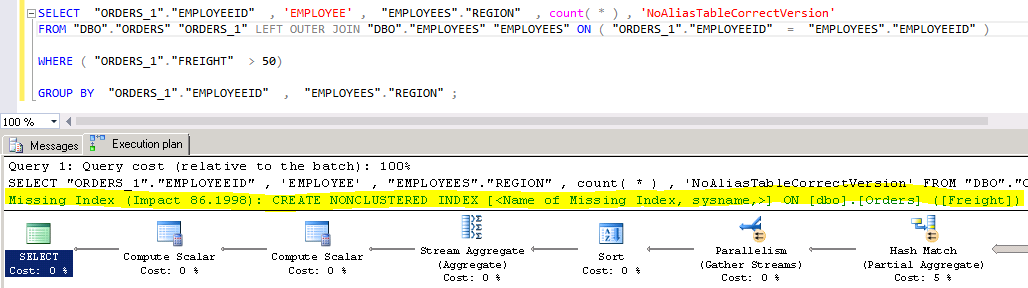
Hier sieht man, dass die Spalte FREIGHT nicht indexiert ist. Mittels einem Index auf diese Spalte könnte die Abfrage beschleunigt werden.
Schritt 4: Analyse der Quelldaten Selektionen – Full Count(*)
Falls First Rows gut funktionieren, kann mittels eines Count(*) über die das gesamte SQL grob ermittelt werden, wie lange es dauert, bis die gesamte Datenmenge gelesen ist.
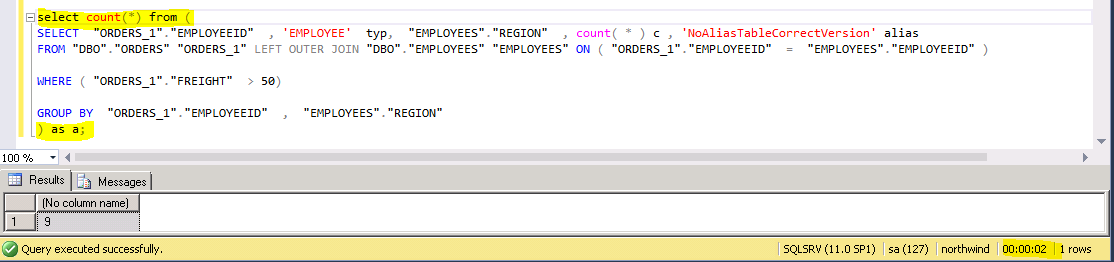
Mit dieser einfachen Analyse kann das Problem bereits soweit eingegrenzt werden, ob die Quellselektion auf der Datenbank oder die Verarbeitung innerhalb des ETL Servers das Problem ist. Sofern die Selektionen auf der Datenbank gut laufen, geht die Suche innerhalb von SAP Data Services weiter.
Schritt 5: Identifikation Engpass innerhalb des ETL Servers
Sofern das Monitor Log nicht bereits eine klare Indikation gibt, in welchem Thread das Problem liegt, wird der Datenfluss Schritt für Schritt zerlegt. Dies kann mittels dem Map_Operation Transform erreicht werden. Zuerst wird das Map_Operation Transform vor der Zieltabelle platziert und alle Operation Codes auf Discard gestellt. So findet man heraus, wie lange der Datenfluss ohne Beladung der Zieltabelle dauern würde.

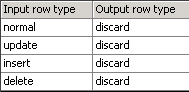
Sind die Ausführungszeiten zwischen der „normalen“ Ausführung und der Ausführung ohne Zieltabelle signifikant unterschiedlich, deutet das darauf hin, dass die Beladung der Zieltabelle das Problem darstellt.
Ist dies nicht der Fall, geht man Schritt für Schritt durch den Datenfluss und platziert das
Map_Operation Transform immer einen Schritt weiter nach vorne, bis der Engpass gefunden ist.
Schritt 6: Redesign Datenfluss
Hat man den Engpass gefunden, gilt es den Datenfluss so umzugestalten, dass die Performance erhöht wird. Dies kann auf unterschiedlichste Weise erreicht werden. Wie genau ein Datenfluss umgestaltet werden kann, um eine verbesserte Performance zu erzielen, erfordert meist langjährige Erfahrung in der Entwicklung mit SAP Data Services und in der Datenbankentwicklung. Ein erster Versuch, die Performance eines Datenflusses zu erhöhen, kann wie oben bereits erwähnt, mittels Ausmerzen der Top Anti-Design-Patterns erreicht werden.
Sie sehen, die Analyse von Performanceproblemen in ETL Jobs erfordert nicht nur Wissen innerhalb des ETL Tools selbst, sondern auch sehr tiefe Kenntnisse der darunterliegenden Datenbank und der physischen Datenmodellierung. Darum kann dieser Überblick zum Vorgehen auch nur an der Oberfläche der Komplexität kratzen, da es in der Praxis noch weit mehr Komponenten zu berücksichtigen gilt wie z.B. Netzwerk, Storage, logisches Datenmodell, Business Anforderungen etc., welche Einfluss auf die Performance von ETL Jobs haben können.
Ich hoffe, dass ich Ihnen hiermit einen guten Einstieg ins Tuning von ETL Jobs geben konnte und freue mich auf Ihre Kommentare.