Die Arbeit eines Data Scientisten ist meist nicht nach der Analyse der Daten und dem Ausarbeiten von Modellen beendet. Sicherlich hat die Datenanalyse schon viele wertvolle Erkenntnisse gebracht, aufgrund derer schon vieles optimiert werden kann. Durch die Modellierung von wichtigen Kerngrössen können aber nicht nur Abhängigkeiten quantifiziert werden, sondern es ist auch möglich aus neuen Daten Kerngrössen vorherzusagen. Durch die periodische Anwendung der ausgearbeiteten Klassifikations- oder Regressionsmodelle auf kürzlich erhaltene Daten liefert kontinuierlich Prognosen, die es erlauben immer einen Schritt voraus zu sein – sei es für die Prognostizierung von Produktnachfrage, das frühzeitige Erkennen von Kundenabwanderung oder auch dem regelmässigen Anpassen von Kundenprofilen, um nur ein paar zu nennen. Mit Azure Data Factory bietet Microsoft eine Cloud Lösung, die es erlaubt, das Anwenden der Machine Learning Modelle und das Zurückschreiben derer Resultate zu automatisieren.
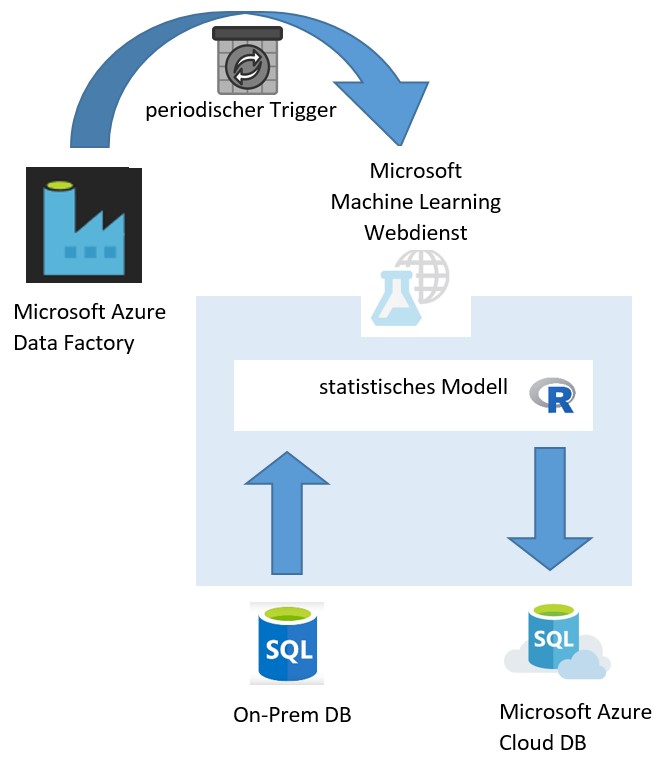
Als Ausgangslage dient ein trainiertes statistisches Modell. Dies soll auf aktuelle Daten auf einer On-Prem DB periodisch angewendet werden und die Resultate sollen zur Weiterverarbeitung auf eine Azure Cloud DB geschrieben werden. Die Berechnung läuft über einen Webdienst, welcher von der Data Factory getriggert wird. (vgl. Abb. 1)
Die vorgestellte Operationalisierung setzt voraus, dass der Benutzer einen Azure Account hat mit einem Data Factory Service, einem Machine Learning Arbeitsbereich und einem Azure Blob Storage. Als Beispiel werden Daten von einer On-Prem MSSQL Datenbank als Eingabe für das Modell benutzt und die Resultate werden auf einer Azure SQL Datenbank abgelegt. Dieser hybride Ansatz ist in vielen Fällen sinnvoll, jedoch wäre es auch denkbar die Resultate wieder auf einer On-Prem Datenbank zu speichern.
ML Studio Web Service
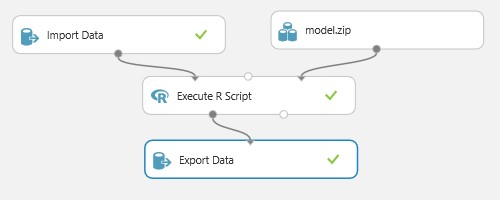
Als erstes wird der Webservice auf Azure Machine Learning Studio erstellt. Dazu muss sichergestellt sein, dass im Azure Portal https://portal.azure.com ein Machine-Learning Arbeitsbereich angelegt ist. Dieser wird benötigt, da die Anbindung an eine On-Prem DB im ML Studio nicht mit einem Free Account möglich ist. Nach der Anmeldung beim Azure Machine Learning Studio (https://studio.azureml.net) kann ein neues Experiment erstellt werden. In Abb. 2 ist ein möglicher Flow abgebildet.
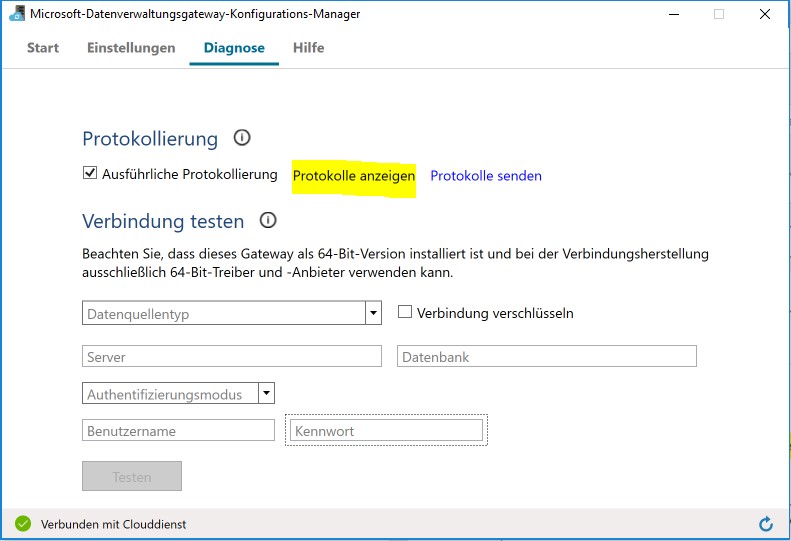
Bei den Einstellungen zum Import Data-Baustein wählt man bei Data Source die Option On Premises SQL Database (Preview Feature). Bei der Option Data Gateway muss ein Gateway heruntergeladen werden, so dass es dann möglich ist von ML Studio auf die On-Prem DB zugreifen zu können. Das Gateway kann über Microsoft-Datenverwaltungsgateway verwaltet werden und unter Diagnose ist es ratsam die Protokollierung zu aktivieren, so können allfällige Probleme schneller erkannt und gelöst werden (Abb. 3). Ebenfalls ist es möglich dort einen Verbindungstest zur DB zu machen.
Es ist ratsam mit dem Edge Browser den Benutzernamen und das Passwort zu konfigurieren, da hierfür ein Credentials Manager nötig ist, welcher nicht mit allen Browsern kompatibel ist. Wie in Abb. 4 dargestellt, kann ein Standard Database Query angegeben werden und durch Anklicken des rechten Icons kann der Wert per Web Service als Parameter gesetzt werden. So können dann immer nur die neusten Daten herausgelesen werden und das Modell darauf angewendet werden. In einem späteren Schritt mehr dazu.

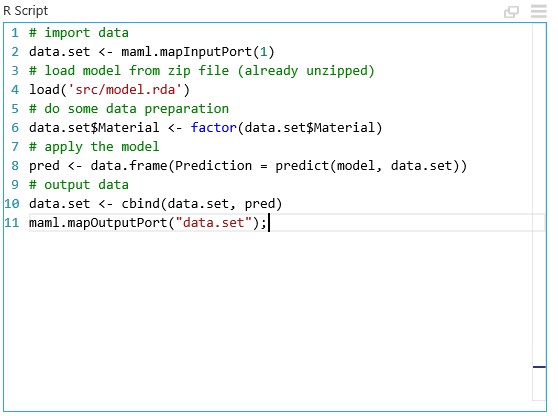
Es gäbe die Möglichkeit Modelle direkt aus dem ML Studio auszuwählen und auf der Basis von Trainingsdaten zu trainieren und zu bewerten. Der hier vorgestellte Ansatz geht aber davon aus, dass das Modell in R vorgängig ausgearbeitet und trainiert wurde. Das anzuwendende Modell wird als rda-Datei aus R exportiert. Damit es in ML Studio importiert werden kann, muss es gezippt werden. Danach kann es als Dataset in ML Studio importiert werden. Mittels R Code können nun die Input Daten aufbereitet werden und das Modell auf die Daten angewendet werden. Ein Beispiel Script ist in Abb. 5 gegeben.
Zum Schluss wird noch die Ausgabe mittels eines Export Data Bausteins in eine Azure SQL DB geschrieben. Leider ist es (noch) nicht möglich von ML Studio direkt wieder in eine On-Prem DB zu schreiben. Falls die Ergebnisse wieder auf eine On-Prem DB geschrieben werden sollen, dann empfiehlt sich einen Web Service Output zu definieren und in der Data Factory Pipeline den Output über einen Azure Blob Speicher in die On-Prem zu kopieren.
Nun muss der Flow einmal durchlaufen und dann kann über die Schaltfläche Deploy Web Service Classic der Web Service erstellt werden. Dieser erwartet einen Parameter für die Steuerung der Query, welche die Daten von der On-Prem DB holt.
Data Factory
Im Azure Portal kann eine Data Factory erstellt werden. Sobald sie erstellt ist, kann unter der Aktion Verfassen und bereitstellen eine Pipeline erstellt werden. Eine Pipeline besteht immer aus einer oder mehreren Aktionen, kann Daten Inputs haben und hat immer mindestens einen Daten Output. Da der kreierte Web Service direkt auf die Daten zugreift und nur mit den richtigen Parametern angestossen werden muss, wird für den Output in der Data Factory nur ein Platzhalter verwendet.
Abb. 6 zeigt ein Beispiel einer möglichen Konfiguration des Verlinkungsdienstes der Data Factory mit dem ML Web Service.

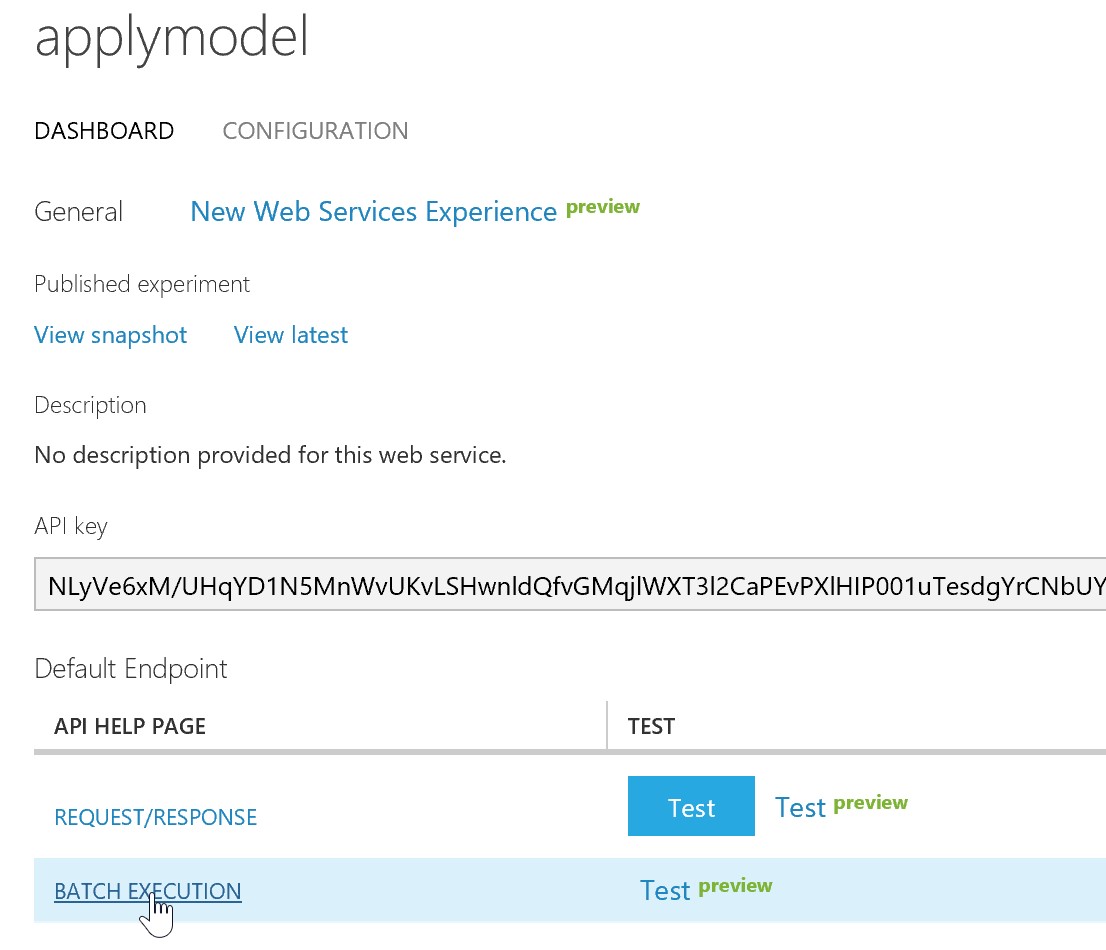
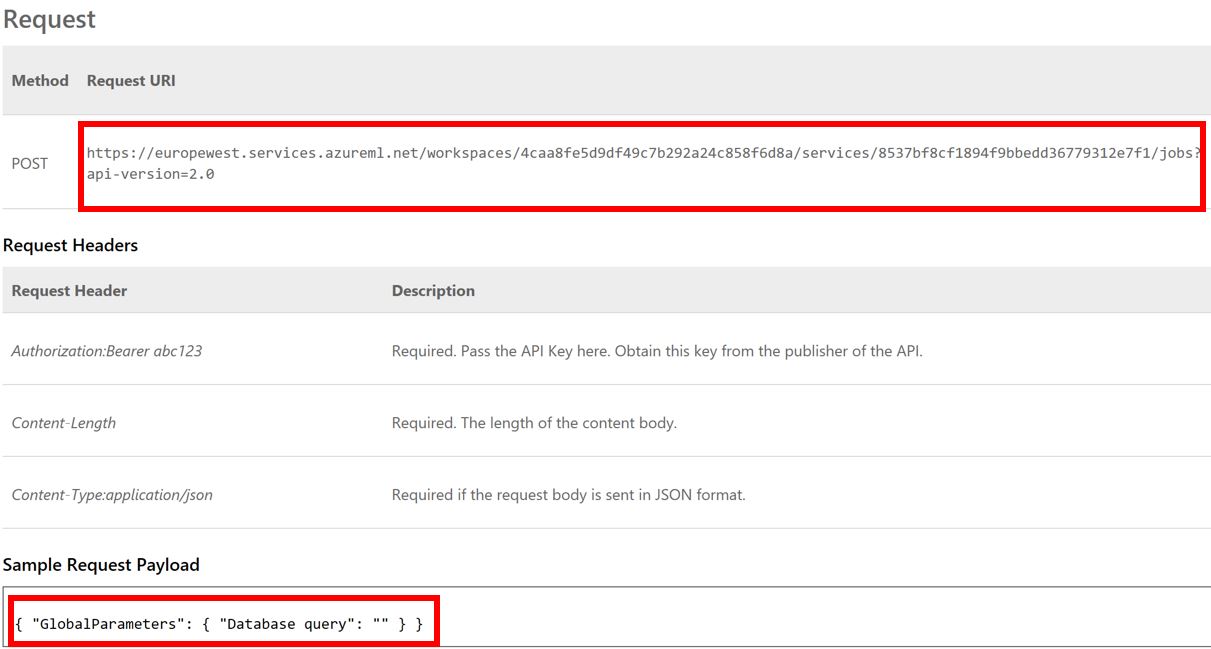
Benötigt wird der ML-Endpoint, welcher man auf dem ML Studio unter dem vorher generierten Web Service in der API Help Page der BATCH EXECUTION findet (vgl. Abb. 7). Dargestellt in Abb. 8 ist die Request URI, welche der benötigte ML-Endpoint ist. Ebenfalls im Dashboard des Web Services (Abb. 7) befindet sich der benötigte API Key.
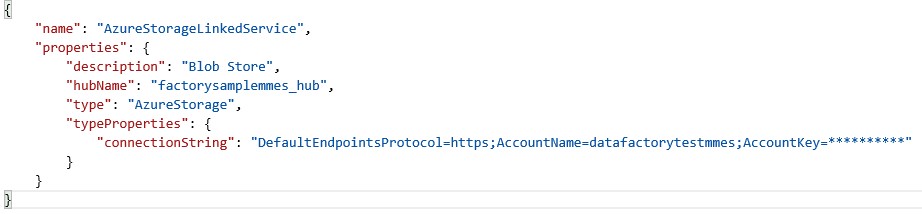
Nun da der verknüpfte Dienst für den Web Service konfiguriert ist, muss noch ein zweiter Dienst konfiguriert werden für den Output Platzhalter der Pipeline. Für Azure ML Aktivitäten braucht es einen Azure Blob Storage Output, daher muss ein neuer Azure Storage Linked Service angelegt werden. Beim connectionString muss der Account Name und der Storage Key angegeben werden, diese sind im Storage account-Bereich unter Einstellungen/Access key zu finden. Untenstehend befindet sich eine Beispielkonfiguration.
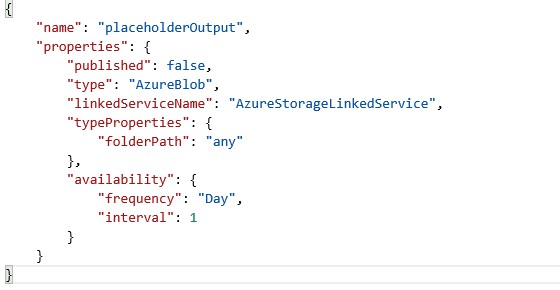
Es kann nun der Platzhalter Output konfiguriert werden, der den gerade eben konfigurierten Verlinkungsdienst verwendet. Eine mögliche Konfiguration zeigt Abb. 10. Unter availability lässt sich die Frequenz angeben, in welcher die Pipeline getriggert wird. Mögliche Werte dort sind Month, Week, Day, Hour und Minute. Mit dem Intervall kann angegeben werden, ob beispielsweise die Pipeline nur jeden dritten Tag ausgeführt werden soll.
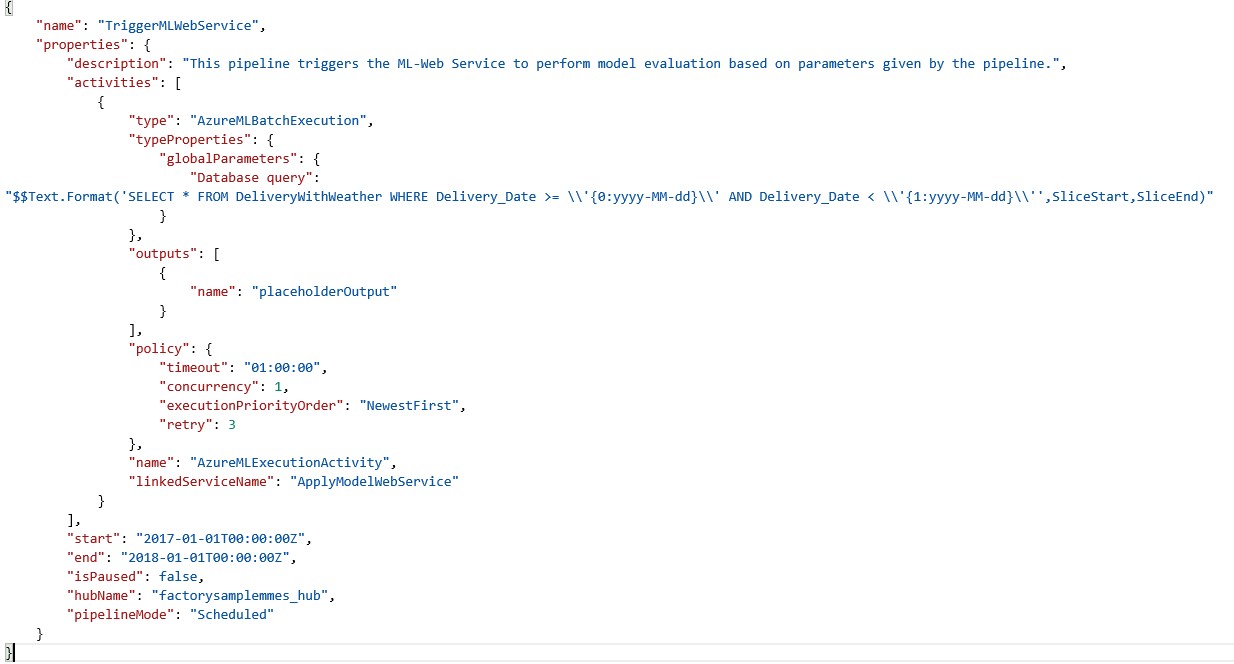
Zum Schluss muss noch die Pipeline selbst konfiguriert werden. Abb. 11 zeigt ein Beispiel einer Konfiguration. Wichtige Punkte sind vor allem, dass die globalParameters so definiert werden, wie sie in der Web Service Dokumentation beschreiben sind (vgl. Abb. 8). SliceStart und SliceEnd sind Variablen, die auf den Ausführungsslice gesetzt sind. Diese sind bei einer täglichen Ausführung zum Beispiel auf zwei aufeinanderfolgende Tage gesetzt. Mithilfe der Text.Format-Funktion kann die SQL Query nach den Pipeline Zeitintervallen angepasst werden. Mehr Informationen dazu findet man unter https://docs.microsoft.com/de-de/azure/data-factory/data-factory-functions-variables. Bei start und end ist die Zeit anzugeben, für die die Pipeline laufen soll. Mit der Variable isPaused kann eine Pipeline aktiviert bzw. deaktiviert werden.
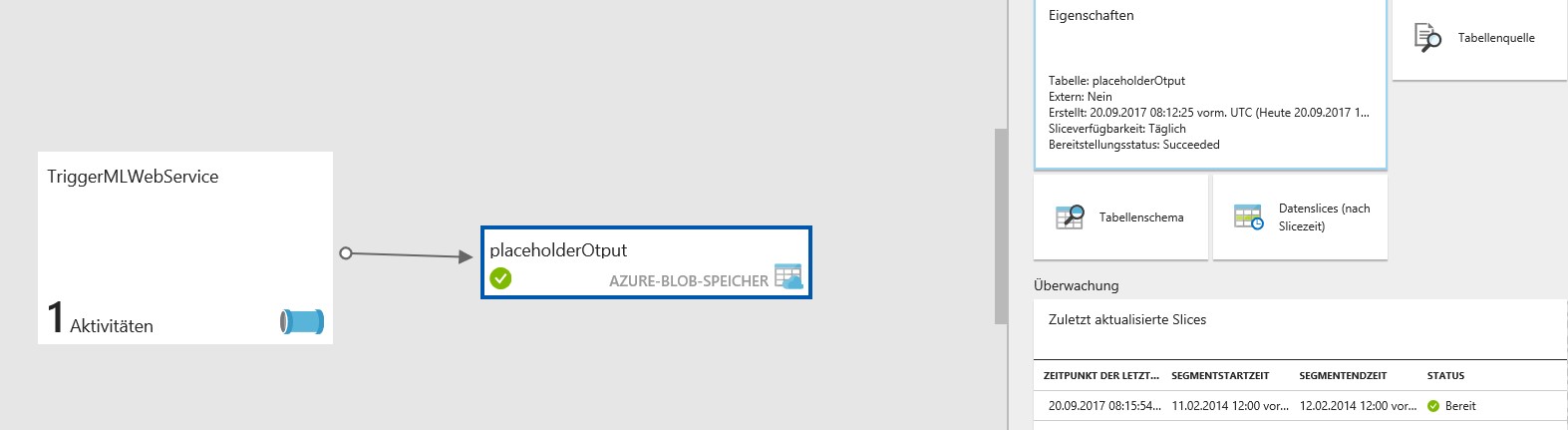
Um zu überprüfen, ob die Ausführung der Pipeline funktioniert, kann über die Schaltfläche Diagramm in der Data Factory Übersicht ein Diagramm des Flows angeschaut werden. Bei Doppelklick auf den Output können unter Überwachung die prozessierten Files angesehen werden.(vgl. Abb. 12)
Zusammenfassung
Es wurde gezeigt, wie ein entwickeltes statistisches Modell mit Machine Learning Studio und Data Factory operationalisiert werden kann. Das Modell wird im Machine Learning Studio in einem Web Service eingebettet, der von der Data Factory periodisch aufgerufen wird. So werden aktuelle gesammelte Geschäftsdaten mit den Machine Learning Algorithmen kontinuierlich ausgewertet und dies vollautomatisch.