Willkommen zurück zu unserer Blogserie über Microsoft Fabric, der innovativen All-in-One-Plattform für Business Intelligence und Datenanalyse. Im ersten Artikel haben wir die vielfältigen Funktionen von Fabric vorgestellt und unsere Erfahrungen mit Data Engineering unter Verwendung von Fabric Notebooks, Python und Spark geteilt. In diesem Artikel möchten wir unsere ersten Eindrücke von Datenarchivierung/Historisierung und Data Warehousing innerhalb von Fabric weitergeben.
Fabric: Lakehouse und Data Warehouse zum automatisierten Archivieren, Aufarbeiten und Bereitstellen von Daten
Zur Erleichterung Ihres Einstiegs bieten wir Ihnen eine kurze Übersicht über Microsoft Fabric. Anschliessend werden wir detailliert das Fabric Lakehouse sowie das Fabric Data Warehouse beleuchten. Diese Elemente eignen sich hervorragend zum Archivieren jeglicher Datenformen, seien sie strukturiert oder unstrukturiert, und zur automatisierten Verarbeitung sowie Bereitstellung strukturierter Daten.
Microsoft Fabric, ein kurzes Recap
Fabric ist eine umfassende Analyseplattform, konzipiert um die Speicherung, Verarbeitung und Analyse von Unternehmensdaten zu revolutionieren. Im Zentrum von Fabric steht OneLake, ein einheitliches Speichermodell, das auf Azure aufbaut und das Delta Lake-Format verwendet. Dieses Modell ermöglicht eine Trennung von Speicherung und Berechnung, was zu verbesserten Leistungs-, Skalierbarkeits-, Sicherheits- und Kostenvorteilen beiträgt.
Fabric Lakehouse
Wie bereits im ersten Teil der Blogserie erwähnt, vereint das Lakehouse die erweiterbaren Speichermöglichkeiten eines Datalakes mit den Datenmanagement- und Analysefähigkeiten eines Data Warehouses. Dies ermöglicht die Verwaltung großer Mengen strukturierter und unstrukturierter Daten. Ein Lakehouse eignet sich daher ideal zur Datenarchivierung. Es kann als erste Stufe einer Datapipeline dienen, um beispielsweise einen Bronze- und Silberlayer zu erstellen. Gleichzeitig mit dem Aufbau des Lakehouses wird ein SQL-Endpunkt bereitgestellt, ein read-only Data Warehouse, das neben dem Standardzugriff über Spark auch den Zugriff auf Daten mittels T-SQL ermöglicht.
Fabric Datawarehouse
Data Warehouses, die auf OneLake basieren, bieten zahlreiche Vorteile gegenüber traditionellen Data Warehouses.
Der signifikanteste Vorteil ist die Time-to-Market: Dank OneLake, der nahtlos integrierten Fabric Lakehouse-Architektur und der Möglichkeit, über Shortcuts eine Vielzahl von Datenquellen anzubinden, sind Daten extrem schnell verfügbar. In Verbindung mit dem automatisch erstellten Power BI-Datensatz können so Datenprodukte schnell erstellt und getestet werden. Das Co-Creating von ersten Prototypen zusammen mit Domänenexperten, um schnellstmöglich den größtmöglichen Businesswert zu generieren, ist effizienter als je zuvor.
Wie bekannt, regt das Essen den Appetit an, und ähnlich verhält es sich mit Reports/Dashboards: Der Ideenfluss beginnt, sobald die Visionäre sehen, was technisch machbar ist. Im Fabric Data Warehouse kann weiterhin Business-Logik mit dem vertrauten T-SQL erstellt werden, ohne notwendigerweise auf Spark-Befehle zurückgreifen zu müssen. Dies ermöglicht auch die Migration bestehender Lösungen von beispielsweise On-Premise-Servern oder Synapse nach Fabric.
Neu ist auch die Time-Travel-Funktion für T-SQL: Diese ermöglicht es, Datenstände ohne spezielle Archivierungsfunktion bis zu sieben Tage in die Vergangenheit einzusehen. Dies eröffnet verschiedene Möglichkeiten, insbesondere im Bereich Reporting und Betrieb. Da sich die Funktion jedoch auf sieben Tage beschränkt, erfüllt sie nicht die klassischen Anforderungen an eine SCD2-Dimension.
Spezialisten für Data Warehousing werden jedoch schnell feststellen, dass die Kombination aus Deltalake-Format und SQL-Engine auch einige Einschränkungen mit sich bringt. So sind einige vertraute Datentypen wie nvarchar oder datetime nicht vorhanden. Auch Funktionen wie Merge oder Truncate stehen (noch) nicht zur Verfügung.
Unsere Erfahrungen mit dem Aufbau kompletter Datenpipelines in Fabric
Bei IT-Logix sind wir von der Data Warehouse-Automatisierung überzeugt. Sie ermöglicht es schnell und ohne Qualitätsverlust konsistente und hochwertige Datenplattformen zu erstellen. Für die Implementierung nutzen wir das Data Warehouse-Automatisierungstool WhereScape. Die Frage ist nun, wie wir WhereScape in Kombination mit Fabric einsetzen können. Wir möchten die Vorteile beider Tools nutzen, ohne auf die jeweiligen Stärken verzichten zu müssen. Die gemeinsame Nutzung der Werkzeuge lässt sich am besten visuell darstellen:
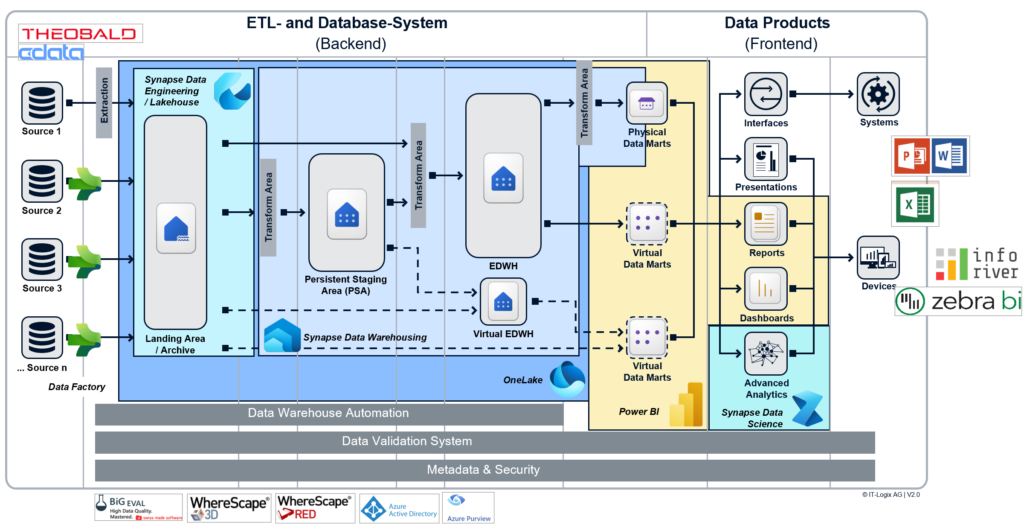
Hier noch ein paar Worte zu unserem Vorgehen:
- Zur Beladung des Fabric Lakehouse nutzen wir Azure Data Factory Pipelines. Dadurch können wir alle Vorteile von Fabric nutzen und eine Vielzahl von Datenquellen anbinden. Mit den Azure Data Factory Pipelines ist es auch möglich, Notebooks zu initiieren, die es erlauben, beliebigen Python-Code auszuführen und komplexe Datenverarbeitungen vorzunehmen. Außerdem lässt sich die Pipeline so konfigurieren, dass Daten automatisch geladen und gespeichert werden, wodurch sich mühelos ein Datenarchiv erstellen lässt.
- Die Warehouse-Komponente ermöglicht einen direkten Zugriff auf die Daten im Fabric Lakehouse mittels T-SQL. Dieses Feature erleichtert es uns, mit WhereScape eine dimensionale Ebene zu erstellen. Die Vorteile von Data Warehouse-Automatisierungstools werden beim Einrichten dieser Ebene deutlich. Dank der Automatisierungsmuster, die wir bei IT-Logix entwickelt und mit WhereScape implementiert haben, ist es für Entwickler nicht mehr notwendig, Code manuell zu schreiben, was bestimmte Probleme verhindert.
Durch Data Warehouse-Automatisierung können wir folgende Risiken minimieren:
a) Duplikate in den Dimensionen
b) Konsistenz zwischen Fakten und Dimensionen durch einen Surrogatschlüssel
c) Late Arriving Dimensionen
d) Etc.
Durch die Automatisierung grundlegender und wiederkehrender Aufgaben kann sich das Projektteam auf die Implementierung der Geschäftslogik und die Erstellung aussagekräftiger Berichte/Dashboards konzentrieren. - Wo WhereScape zum Einsatz kommt, hat der Entwickler Zugang zu einer umfangreichen Auswahl an Metadaten und anderen nützlichen Werkzeugen. Nutzer können beispielsweise jederzeit die gesamte Data-Lineage, von der Quelle bis zu den Berichten, visuell oder tabellarisch darstellen, analysieren und Probleme umgehend lösen – denn Blackbox-Logik ist nicht erwünscht.
Auch im Controlling können Metadaten ideal eingesetzt werden, um generische Unittests zu erstellen, die auch bei Erweiterungen der Datenplattform keine Anpassungen erfordern.
Zudem lässt sich das gesamte Projekt jederzeit dokumentieren und verschiedene Versionen einzelner Objekte können erstellt werden. Dies ermöglicht es, bei Bedarf Zustände aus der Vergangenheit wiederherzustellen oder auch wieder in die Zukunft zu springen.
Fazit
Fabric ist derzeit noch nicht mit allen bekannten und gewünschten Funktionen ausgestattet und stellt auch noch keine Near-No-Code-Lösung dar. Die zahlreichen Vorteile der Fabric-Architektur, einschließlich OneLake, Lakehouse, Data Warehouse und verschiedener Schnittstellen wie Direct Lake, lassen sich momentan nur über Notebooks oder mit anderen Azure-Komponenten vollständig nutzen.